○ принять решение о том, нужно ли пересматривать цену. Если ситуация классифицируется как прибыльная, то никаких мер не принимается. Если же ожидаются убытки, следует пересмотреть цену.
Таким образом, решение, принимаемое в описываемой задаче, вспомогательное и служит лишь для инициации дальнейшей работы.
Для иллюстрации методов принятия решения-классификации требуется набор ситуаций для обучения системы. Обычно он берется из опыта. Даже если в свое время было принято неправильное решение, время обычно показывает его ошибочность, и становится ясно, как надо было поступать.
Имеющийся набор ситуаций представлен на рис. 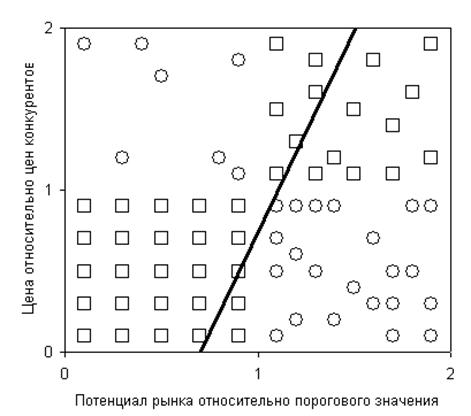
Рис. 44. Квадратами отмечены ситуации, нуждающиеся в изменении, кругами – не нуждающиеся. В данном случае набор ситуаций для обучения создан произвольно. Чтобы не перегружать примеры, принимается, что все случаи расположены строго внутри своей области соответственно вышеприведенной таблице. Это некоторое упрощение. Реально области различных решений могут пересекаться.
В компьютере данные хранятся в таблице с тремя столбцами: потенциал рынка относительно порогового значения; цена относительно средней цены конкурентов; принимаемое решение (0 – не изменять, 1 – изменять).
Дискриминантный анализ призван помочь решить, к какому классу отнести ситуацию, то есть в данном случае – стоит ли изменять цену, если известны переменные-причины: относительная цена на товар и относительный потенциал рынка. Для этого строится линейная комбинация этих переменных. Это можно сделать с помощью пакетов Statistica или SPSS.
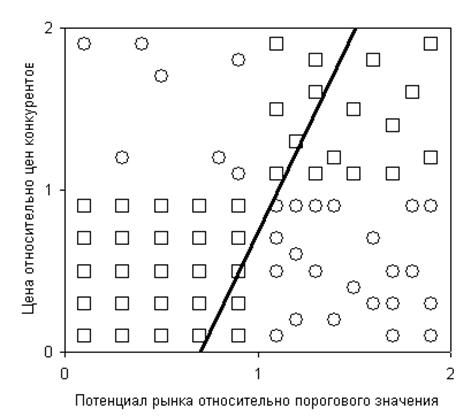
Рис. 44. Данные о правильных решениях для прошлых случаев аудита
Полученное решение (рис. Рис. 45) представляет собой коэффициенты дискриминантной функции вида
А*Потенциал+В*Цена+С.
На рис. Рис. 45 коэффициенты А, В, С представлены сверху вниз.
Разделять ситуации на два класса можно по знаку этой функции: если полученное значение для какой-либо ситуации больше нуля, то она не нуждается в пересмотре, иначе нуждается.
Прямая линия, соответствующая нулевому значению дискриминантной функции, то есть уравнению
А*Потенциал+В*Цена+С=0,
проведена на рис.
Рис. 44. Точки, расположенные левее нее, не нуждаются в пересмотре, правее – нуждаются. Правильный ответ был найден примерно для 73% имеющихся точек, о чем свидетельствует рис. Рис. 46, также являющийся результатом дискриминантного анализа и содержащий оценки точности прогнозов.
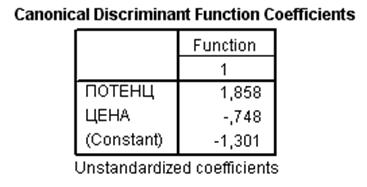
Рис. 45. Результат дискриминантного
анализа,
полученный с помощью пакета SPSS 11.5
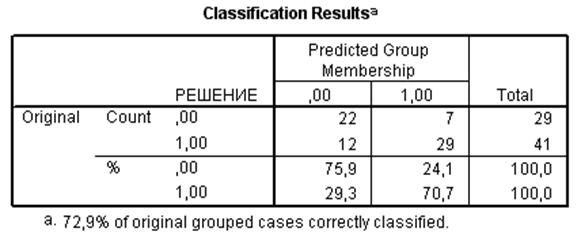
Рис. 46. Результаты классификации и оценка ошибок
Из последнего столбца таблицы, изображенной на рис. Рис. 46 (Total – итог) видно, что в исходном наборе ситуаций 29 не требовали пересмотра и 41 требовала. Эти решения обозначены соответственно как ,00 и 1,00 (фактически 0 и 1) в первом столбце таблицы, имеющем название РЕШЕНИЕ. Из столбцов под общим названием Predicted Group Membership (предсказанная принадлежность к группе) видно, что из 29 ситуаций с решением 0 (не изменять) 22 были классифицированы правильно, а 7 – неверно. Из 41 ситуации, нуждающейся в пересмотре, 12 были ошибочно классифицированы как не требующие пересмотра, а 29 идентифицированы правильно. Нижняя часть таблицы представляет эти же данные в процентах.
Таким образом, хотя дискриминантный анализ дал определенный прогноз (наилучший для данного класса решений, когда области разделяются прямой линией), вероятность ошибки очень велика. Каждое третье решение принимается неправильно. Как было показано выше, для новых случаев вероятность ошибки будет не меньше. Это объясняется неудачным расположением ситуаций различного типа в пространстве причинных переменных. Если бы ситуации с различными решениями образовывали две обособленные области, прогноз мог бы быть точным.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.