Наконец, столбцы Interarrival Time Distribution (распределение времени между моментами прибытия) и Service Time Distribution (распределение времени обслуживания) определяют вид закона распределения (словесно) и его параметры (в виде одного или нескольких чисел, разделенных слешем).
Перед моделированием задается также единица времени (минута) и длительность моделирования (480 минут).
Результаты моделирования. После запуска модели на выполнение можно просмотреть результаты одного прогона моделирования.
На рис. Рис. 39, Рис. 40, Рис. 41 показаны таблицы результатов по покупателям, очередям и каналам обслуживания соответственно.
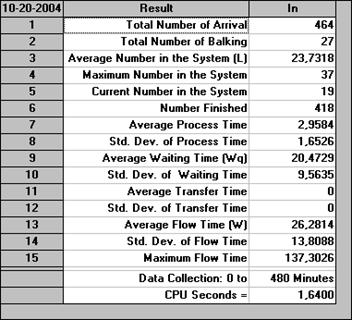
Рис. 39. Таблица результатов моделирования: сведения о покупателях
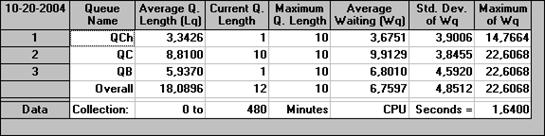
Рис. 40. Таблица результатов моделирования: сведения об очередях
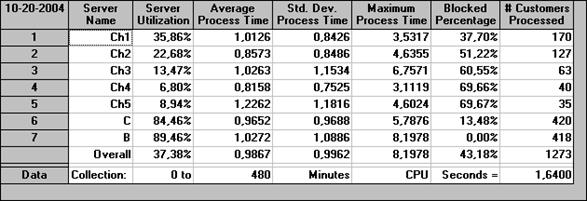
Рис. 41. Таблица результатов
моделирования:
сведения о каналах обслуживания
Из таблицы, показанной на рис. Рис. 39, чаще всего представляют интерес следующие параметры:
○ 1 (число заявок),
○ 2 (число отказов); в примере оно составило 27 из 464 пришедших, что можно считать достаточно малой величиной;
○ 9 (среднее время ожидания); видно, что именно ожидание и составляет большую часть времени, проводимого покупателями в магазине;
○ 13 (среднее время нахождения в системе).
Параметр 5 (текущее количество в системе) показывает, сколько покупателей осталось в магазине после завершения его работы. Видно, что это количество составило примерно 4% от общего числа пришедших в магазин, что может сказаться на точности полученных оценок, хотя, очевидно, не очень сильно.
Таблица, изображенная на рис. Рис. 40 показывает:
○ средние длины каждой очереди (столбец Average Q Length);
○ среднее время ожидания в очереди (Average Waiting), из которого видны наиболее проблемные очереди
и другие параметры.
Таблица, данная на рис. Рис. 41, показывает такие параметры, как:
○ среднее время обслуживания (Average Process Time);
○ число обслуженных заявок (# Customers Processed);
○ процент времени нахождения в заблокированном состоянии (Blocked percentage)
и другие.
Следует обратить внимание на большие значения процента нахождения в заблокированном состоянии, что говорит о сильном отклонении алгоритма работы модели от желаемого. Если бы эти значения составляли несколько процентов или менее, что произошло бы при меньших очередях, можно было бы считать допущение 7 несущественным. Но для исследования наиболее интересны как раз те режимы, когда система перестает справляться с потоком заявок. Для них обычно и требуется предложить какое-либо усовершенствование.
Результаты моделирования можно представить в графической форме. С развитием офисных приложений графическое представление табличных данных перестало быть проблемой. Но имитационные программы обычно дают и графические результаты. Для примера рассматриваются сравнительные величины, характеризующие поток заявок (рис. Рис. 42) и очереди (рис. Рис. 43).
На рис. Рис. 42 ось ординат показывает количество покупателей, столбцы диаграммы и пункты легенды имеют значение (слева направо и сверху вниз соответственно):
○ общее число заявок;
○ общее число отказов;
○ среднее число заявок в системе (L);
○ максимальное число заявок в системе;
○ текущее число заявок в системе, оставшееся после окончания моделирования;
○ число заявок, для которых обслуживание было завершено.
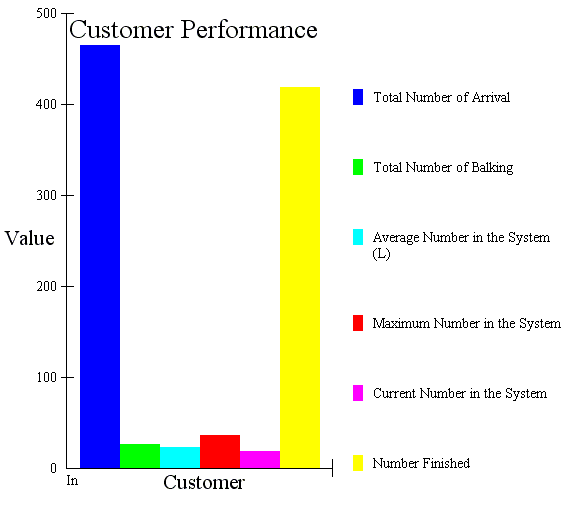
Рис. 42. Характеристики потока заявок
Рис. Рис. 43 показывает время нахождения в очередях в минутах. Обозначения очередей соответствуют рис. Рис. 37. Последняя группа (Overall) отражает средние значения по всем очередям. Левый столбец каждой пары (и верхний пункт легенды) соответствует среднему времени ожидания в очереди, а правый столбец (и нижний пункт легенды) – максимальному.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.