1. Провести первичную обработку статистических данных (включая проверку данных). Результаты представить в виде таблиц. Построить статистические ряды для каждого признака.
2. Построить гистограмму, полигон относительных частот и кумуляту по каждому признаку.
3. Используя метод “условного нуля”, определить числовые характеристики выборок по каждому признаку: выборочное среднее; выборочную дисперсию; исправленную выборочную дисперсию; исправленное выборочное среднее квадратическое отклонение. Дать объяснение полученным результатам.
4. Для каждого признака построить 99% или 95% доверительные интервалы для оценки генеральных средних, генеральных средних квадратических отклонений. Дать объяснение полученным результатам.
5. При уровне значимости a=0,05 или a=0,1 проверить гипотезы о нормальных законах распределения генеральных совокупностей по каждому признаку.
6. Для признаков X и Y построить корреляционное поле, эмпирическую ломанную регрессии и дать предварительный анализ зависимости между признаками.
7. Для признаков X и Y вычислить эмпирический коэффициент детерминации и эмпирическое корреляционное отношение.
8. Определить параметры уравнения линейной регрессии.
9. Определить коэффициент корреляции и проверить его на значимость. Сделать вывод о наличии линейной связи между признаками.
10. Составить нелинейное уравнение регрессии, выбрав подходящий тип нелинейности.
11. Построить полученные линии регрессии в одной системе координат.
12. Для всех моделей рассчитать теоретический коэффициент детерминации и теоретическое корреляционное отношение; среднюю квадратическую погрешность уравнения; среднюю относительную погрешность аппроксимации.
13. Используя лучшее из полученных уравнений регрессии дать точечный прогноз значения У при мощности пласта X = 1,8м .
![]() Решение
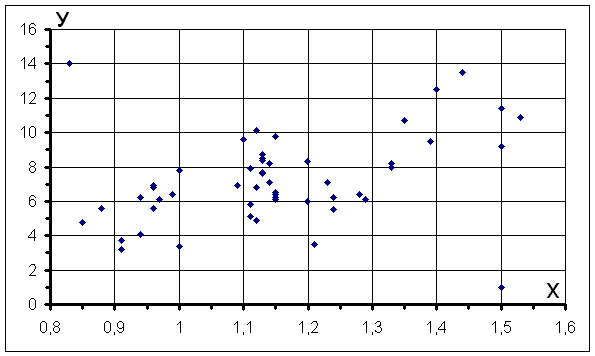
задачи начнем с проверки исходных данных. Построим корреляционное поле, в
котором будут представлены 52 точки (объем выборки n = 52).
Решение
задачи начнем с проверки исходных данных. Построим корреляционное поле, в
котором будут представлены 52 точки (объем выборки n = 52).
Из построенной диаграммы видим, что две точки (0,83; 14) и (1,5; 1) “выскакивают” из общей совокупности. Анализ исходных данных с позиции возможности большой производительности (у=14 т/вых) при малой мощности пласта (х = 0,83 м) и малой производительности (у=1 т/вых) при большой мощности пласта (х=1,5 м) позволяет отнести эти точки к ошибочным и исключить их из дальнейшего рассмотрения. Следовательно, объем выборки на этом этапе принимается n = 50.
Продолжим решение задачи.
а) Для признака Х определим наибольшее и наименьшее значение признака: Xmin=0,85 ; Xmax=1,53 ;
Число интервалов разбиения определим по формуле Стэрджесса:
k =1 + 3,322× lg n = 1 + 3,322× lg 50 = 6,6 » 7.
Найдем шаг разбиения h = (Хmax – Xmin) / k.
В данном случае h = (1,53 – 0,85) / 7 = 0,097. Примем h = 0,1.
Произведем группировку данных для признака Х. Для этого подсчитаем, сколько значений признака Х попадет в каждый из интервалов разбиения. Причем, при совпадении значения признака с одной из границ интервала, включаем это значение в левый интервал. Результаты группировки заносим в табл.2. В третьем столбце таблицы заносятся штриховые отметки. Это удобный прием подсчета частот. Начинают с первого элемента выборки. В нашем случае он равен 1,13. Затем находят интервал (1,05 – 1,15), в который это наблюдение попадает, и ставят в третьем столбце штриховую отметку. Остальные наблюдения обрабатывают аналогично в том порядке, в котором они представлены в начальной выборке.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.