· ANOVA/MANOVA – Модуль дисперсионного анализа
· Classification Trees – Модуль Классификационное дерево
· Data Management – Модуль Управление данными
· Quality Control –Модуль Контроль качества
Более подробная информация о работе с данными в среде STATISTICA содержится в [3 ]
Для примера возьмем задачу о нахождении уравнения множественной регрессии, которая решалась нами средствами пакета Mathcad в пункте 5.8 и в среде Excel в пункте 6.1.
а) Заполняем данными исходную таблицу ( приводим фрагмент таблицы):
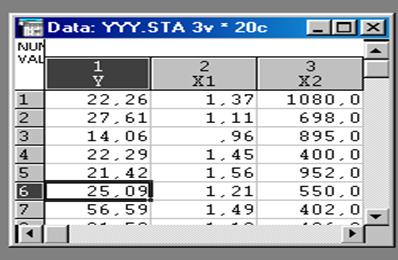
б) Используя переключатель модулей, переходим в модуль Множественная регрессия.
Выбираем зависимые (dependent -У) и независимые (independent X1, X2) переменные (variables). После нажатия кнопки ОК результаты можно вывести в виде таблицы
|
Regression Summary for Dependent Variable: Y (yyy.sta) |
||||||
|
R= ,78210169 RІ= ,61168305 Adjusted RІ= ,56599870 |
||||||
|
F(2,17)=13,389 p<,00032 Std.Error of estimate: 7,3732 |
||||||
|
St. Err. |
St. Err. |
|||||
|
BETA |
of BETA |
B |
of B |
t(17) |
p-level |
|
|
Своб.член |
10,986 |
12,145 |
0,905 |
0,378 |
||
|
X1 |
0,454 |
0,163 |
23,471 |
8,412 |
2,790 |
0,013 |
|
X2 |
-0,490 |
0,163 |
-0,018 |
0,006 |
-3,007 |
0,008 |
Здесь R=0,782 – корреляционное отношение; RI=0,612 – коэффициент детерминации; F(2,17)=13,389 – наблюдаемое значение критерия Фишера; p<0,00032 – значимость ошибки первого рода, при которой гипотезу об адекватности полученной модели нужно отвергнуть. Малая вероятность говорит о том, что модель адекватная.
Параметры модели содержатся в столбце В. Они совпадают с найденными ранее. В следующих столбцах помещены СКО этих параметров; их t-статистики и уровни вероятностей ошибок. Если выбрать значимость a=0,1 , то коэффициенты регрессии при Х1 и Х2 признаются значимыми, свободный член уравнения регрессии признается незначимым. Это значит, что нужно выбрать другую спецификацию модели, возможно без свободного члена.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.