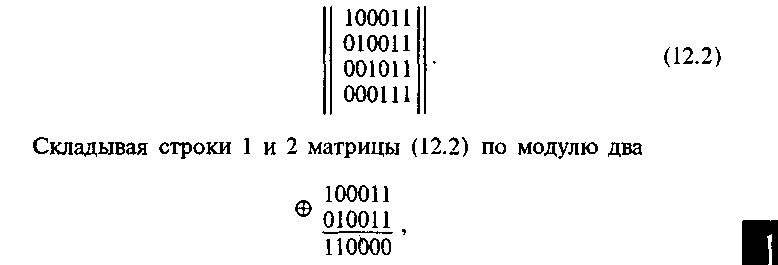
Np = Naразрешенных кодовых комбинаций надо выбирать такие, которые максимально отличаются друг от друга.
Пример 12.2. Алфавит передаваемых сообщений Na = 2. Выберем из числа комбинаций, представленных в табл. 12.1, две. Очевидно, что ими должны быть комбинации 000, 111 или 001 и 110 и т.д. Кодовое расстояние d0= 3. Ошибки кратности один или два превращают любую разрешенную кодовую комбинацию в запрещенную. Следовательно, максимальная кратность обнаруживаемых таким образом ошибок равна двум
(to.oш=2) ,
Нетрудно догадаться, что минимальное кодовое расстояние dо и гарантированно обнаруживаемая кратность ошибок связаны соотношением tоош = dO- 1.
Исправление ошибок возможно также только в том случае, если переданная разрешенная кодовая комбинация переходит в запрещенную. Вывод о том, какая кодовая комбинация передавалась, делается на основании сравнения принятой запрещенной комбинации со всеми разрешенными. Принятая комбинация отождествляется с той из разрешенных, на которую она больше всего похожа, т.е. с той, от которой она отличается меньшим числом элементов. Так, если в примере 12.2 при передаче кодовой комбинации 000 получим 001, то вынесем решение, что передавалась кодовая комбинация 000.
Связь между d0и кратностью исправляемых ошибок определяется выражением tИош = (d0/2) - 1 для четного d0и и tош = (do - 1)/2 для нечетного d0.
Итак, задача получения кода с заданной корректирующей способностью сводится к задаче выбора (путем перебора) из N0= 2" кодовых комбинаций Naкомбинаций с требуемым кодовым расстоянием d0. Если п достаточно мало, то такой перебор не представляет особого труда. При больших п перебор может оказаться непосильным даже для современной ЭВМ, поэтому на практике используют методы построения кодов, не требующие перебора с целью получения кода с заданным d0и отличающиеся невысокой сложностью реализации.
Классификация корректирующих кодов. Помехоустойчивые или корректирующие коды (рис. 12.1) делятся на блочные и непрерывные. К блочным относятся коды, в которых каждому символу алфавита сообщений соответствует блок (кодовая комбинация) из n(i) элементов, где
i — номер сообщения. Если n(i) = п, т.е. длина блока постоянна и не зависит от номера сообщения, то код называется равномерным. Такие коды чаще применяются на практике. Если длина блока зависит от номера сообщения, то блочный код называется неравномерным. Примером неравномерного кода служит код Морзе. В непрерывных кодах передаваемая информационная последовательность не разделяется на блоки, а проверочные элементы1 размещаются в определенном порядке между информационными.
Равномерные блочные коды делятся на разделимые и неразделимые. В первых элементы разделяются на информационные и проверочные, занимающие определенные места в кодовой комбинации, во вторых отсутствует деление элементов кодовых комбинаций на информационные и проверочные. К последним относится код с постоянным весом, например рекомендованный Международным консультативным комитетом по телефонии и телеграфии (МККТТ), семиэлементный телеграфный код № 3 с весом каждой кодовой комбинации, равным трем.
Примерами систематических являются коды Хемминга и циклические. Последние реализуются наиболее просто, что и
Проверочные элементы в отличие от информационных, относящихся к исходной последовательности, служат для обнаружения и исправления ошибок и формируются по определенным правилам.
|
|
|
|
|
|
привело к их широкому использованию в УЗО. Для систематического кода применяется обозначение (п,k) — код, где п — число элементов в комбинации; k— число информационных элементов.
Характерной особенностью этих кодов является также и то, что информационные и проверочные элементы связаны между собой зависимостями, описываемыми линейными уравнениями. Отсюда возникает и второе название систематических кодов — линейные.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.