o PC/IXF - файлы PC Integrated Exchange Format (интегрированный формат обмена ПК)
o WSF - файлы формата электронных таблиц
Для поддержки процедур загрузки и извлечения данных в DB2 существует ряд утилит:
o Утилита EXPORT - используется для извлечения информации из таблицы базы данных в файлы данных различных форматов (IXF, DEL или WSF)
o Утилита IMPORT - заносит данные из входного файла в таблицу или в вид, если таблица уже содержит данные
o Утилита LOAD - так же как и утилита IMPORT, перемещает в таблицу назначения данные, представленные во входном файле. В отличие от утилиты IMPORT таблица назначения должна существовать в базе данных до начала загрузки
o Утилита DB2MOVE - используется для перемещения данных между различными базами данных, с использованием промежуточных внешних файлов
o Утилита DB2LOOK - выдает отчеты о структуре данных в БД. Эта информация может быть использована при перемещении данных
Все эти утилиты могут быть вызваны как из Command Center, так и из Control Center.
· Анализ данных - При использовании утилит перемещения данных с большими объемами данных администратор должен учитывать фактор производительности, т.е. производить анализ организации данных и настройку параметров утилит загрузки и извлечения данных (для каждой утилиты эти параметры свои собственные) в зависимости от результатов этого анализа. При настройке следует учитывать особенностей физического размещения данных (их можно узнать с помощью утилиты REOGCHK), перед загрузкой или извлечением данных в случае необходимости, в том числе и для увеличения производительности может производиться реорганизация данных с помощью утилиты REORG.
На классовой диаграмме, представленной на рисунке 2.11, показана логическая организация процесса поддержки данных.
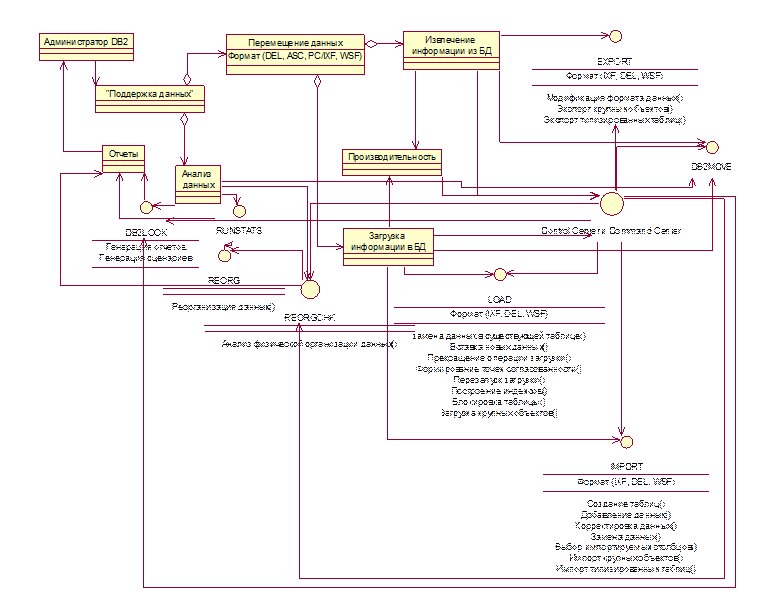
Рис. 2.11. Логическая организация процесса поддержки данных. (Классовая диаграмма).
При больших объемах БД, большом числе пользователей и запросов в единицу времени, встает вопрос о необходимости распараллеливания операций. Выделяют два типа параллелизма аппаратный (увеличение числа процессоров – схемы SMP и MPP) и программный параллелизм, позволяющий одному пользователю не дожидаться окончания работы другого. Для обеспечения этого типа параллелизма необходимо распараллелить работу утилит, интерфейсов ввода/вывода и обработку запросов, что и сделано в СУБД DB2.
Рассмотрим подробнее подзадачи, входящие в состав задачи "Параллелизм":
· аппаратный параллелизм - повышение производительности базы данных может достигаться путем увеличения числа процессоров в вычислительной системе, тем самым появляется возможность параллельной обработки запросов на различных процессорах, при этом суммарная скорость обработки данных скорость от (20 до 80 %) * число процессоров. Увеличение скорости обработки данных при использовании аппаратного параллелизма (мультипроцессорности) зависит от многих факторов, в том числе от выбранной мультипроцессорной конфигурацией (SMP, MPP), а также от наличия и эффективности реализации программного параллелизма (если программный параллелизм отсутствует, т.е. в системе нет параллельно выполняющихся процессов, то эффект от использования не одного, а нескольких процессоров будет нулевой).
· программный параллелизм - в отличие от аппаратного, программный параллелизм сам по себе не увеличивает скорость обработки данных, однако создает возможности:
o одновременного запуска нескольких приложений (параллелизм утилит)
o одновременного чтения нескольких файлов данных (параллелизм ввода/вывода)
o возможность одновременной работы нескольких пользователей и приложений (параллелизм запросов)
При использовании программного параллелизма возникает ряд аномалий, а именно:
o Потерянное обновление
o Чтение незафиксированных данных
o Неповторяемое чтение
o Фантомное чтение
Эти аномалии устраняются с помощью использования механизма блокировок
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.