char *nodes[] = read_nodes();
AtmOcn atm, ocn;
atm.init(P, nodes); // Изменения произошли
ocn.init(P, nodes); // только в этих строчках
par
{
atm.atmosphere();
ocn.ocean();
}
}
Описанные модели показали варианты использования конструкций CC++ для осуществления параллельной и совместно действующей композиции процессорных объектов. Основная идея проста: каждый узел многокомпонентной программы представляется в виде отдельной задачи. Каждой такой задаче придан массив объектов типаproc_t, представляющих ее вычислительные ресурсы. Задача создает явный набор процессорных объектов, отображает их на процессоры (объекты типаproc_t) и устанавливает связь между процессорами и процессорными объектами.
Рассмотрим методы осуществления последовательных композиций в программах СС++ на примере вычисления элементов результирующей матрицы, равной произведению двух квадратных матриц:
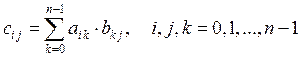 ,
,
где ![]() элементы плотных матриц
элементы плотных матриц ![]() размера
размера ![]() .
.
Общее число вычисляемых компонент ![]() равно
равно ![]() .
Программа вычисления суммы произведений одинакова для любой компоненты
результирующей матрицы. Следовательно, имеется столько же одинаковых задач
(процессов), которые можно выполнять последовательно в любом порядке, в том
числе и одновременно. Для больших матриц число процессоров всегда будет
существенно меньшим. Вся вычислительная работа по формированию матрицы лежит на
главном, корневом процессе, который распределяет исходные данные и собирает
результаты работы каждого процесса в нужное представление результирующей
матрицы. Это типичная задача вычислительных систем типа SPMD (Single Program
Multiple Data). Каждый неделимой процесс такой задачи может самостоятельно
передавать результаты и синхронизировать свою работу с другими процессами,
однако создавать новую задачу эти процессы не могут.
.
Программа вычисления суммы произведений одинакова для любой компоненты
результирующей матрицы. Следовательно, имеется столько же одинаковых задач
(процессов), которые можно выполнять последовательно в любом порядке, в том
числе и одновременно. Для больших матриц число процессоров всегда будет
существенно меньшим. Вся вычислительная работа по формированию матрицы лежит на
главном, корневом процессе, который распределяет исходные данные и собирает
результаты работы каждого процесса в нужное представление результирующей
матрицы. Это типичная задача вычислительных систем типа SPMD (Single Program
Multiple Data). Каждый неделимой процесс такой задачи может самостоятельно
передавать результаты и синхронизировать свою работу с другими процессами,
однако создавать новую задачу эти процессы не могут.
Конечно-разностные методы решения [17] многомерных систем дифференциальных уравнений в частных производных в большинстве своем тоже сводятся к параллельным структурам, размещаемым в SPMD.
Реализация CC++ программы со структурой SPMD включает в себя две компоненты. Инициализацию, которая создает процессорные объекты для выполнения вычислений и структуры связи (например, каналы), необходимые программным компонентам, входящим в последовательные композиции, и исполнение, где совершаются вычисления с использованием созданных во время фазы инициализации структур. Исполняемая компонента структурно может быть представлена двумя различными способами (Рисунок 3.8).
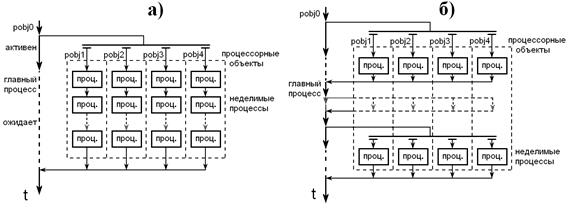 На рисунке 3.8 временные оси
представляют коренной вычислительный процесс. Его активные интервалы
представлены сплошными отрезками, а интервалы ожидания – пунктирными. Фаза
инициализации в обоих случаях создает четыре процессорных объекта, в которых
будут происходить вычисления. На рисунке слева программа верхнего уровня в
каждом процессорном объекте скомпонована в виде последовательно вызываемых
подпрограмм, которые оператором parfor
порождают в нем локальный вычислительный процесс. На правом рисунке
единственный оператор parfor
коренного процесса порождает последовательность вызовов параллельных
подпрограмм, которые скомпонованы так, что на каждом процессорном объекте
находится лишь по одному неделимому процессу. Первый вариант может привести к
более простым программам, но последний имеет тенденцию быть более эффективным.
На рисунке 3.8 временные оси
представляют коренной вычислительный процесс. Его активные интервалы
представлены сплошными отрезками, а интервалы ожидания – пунктирными. Фаза
инициализации в обоих случаях создает четыре процессорных объекта, в которых
будут происходить вычисления. На рисунке слева программа верхнего уровня в
каждом процессорном объекте скомпонована в виде последовательно вызываемых
подпрограмм, которые оператором parfor
порождают в нем локальный вычислительный процесс. На правом рисунке
единственный оператор parfor
коренного процесса порождает последовательность вызовов параллельных
подпрограмм, которые скомпонованы так, что на каждом процессорном объекте
находится лишь по одному неделимому процессу. Первый вариант может привести к
более простым программам, но последний имеет тенденцию быть более эффективным.
Рисунок 3.8. Варианты последовательно-параллельных вычислений в SPMD.
void finite_difference()
{
parfor (int i=0; i<P; i++)
nodes[i]->finite_diff(i);
}
void main(int argc, char *argv[])
{
int P = atoi(argv[1]);
int done = FALSE;
// Инициализация, создающая массив процессорных объектов, узлов
initialize(P);
// Выполнение вычислений в процессорных объектах
while(!done)
{
finite_difference();
globmax = global_maximum();
if (globmax < threshold) done = TRUE;
}
}
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.