Входные параметры этой подпрограммы:
· sendbuf — начальный адрес буфера передачи;
· sendcount — количество элементов в буфере передачи;
· sendtype — тип передаваемых данных;
· rcvcount — количество элементов, полученных от каждого процесса;
· rcvtype — тип данных в буфере приема;
· comm — коммуникатор.
Выходным параметром является адрес буфера приема (rcvbuf). Блок данных, переданный от j-того процесса, принимается каждым процессом и размещается в j-м блоке буфера приема recvbuf.
Подпрограмма MPI_Alltoall пересылает данные по схеме "каждый — всем":
int MPI_Alltoall(void *sendbuf, int sendcount,
MPI_Datatype sendtype, void *rcvbuf,
int rcvcount, MPI_Datatype rcvtype,
MPI_Commcomm)
Входные параметры:
· sendbuf — начальный адрес буфера передачи;
· sendcount — количество элементов данных, пересылаемых каждому процессу;
· sendtype — тип данных в буфере передачи;
· rcvcount — количество элементов данных, принимаемых от каждого процесса;
· rcvtype — тип принимаемых данных;
· comm — коммуникатор.
Выходной параметр — адрес буфера приема rcvbuf. Векторными версиями MPI_Allgather и MPI_Alltoall являются подпрограммыMPI_Allgatherv и MPI_Alltoallv. Подпрограмма MPI_Allgatherv собирает данные от всех процессов и пересылает их всем процессам:
int MPI_Allgatherv(void ^sendbuf, int sendcount,
MPI_Datatype sendtype, void *rcvbuf,
int *rcvcounts, int *displs,
MPI_Datatype rcvtype, MPI_Comm comm)
Ее параметры совпадают с параметрами подпрограммы MPI_Allgather, за исключением дополнительного входного параметра displs. Это целочисленный одномерный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент массива с индексом i задает смещение относительно начала буфера приема recvbuf, в котором располагаются данные, принимаемые от процесса i. Блок данных, переданный от j-го процесса, принимается каждым процессом и размещается в j-м блоке буфера приема.
Подпрограмма MPI_Alltoallv пересылает данные от всех процессов всем процессам со смещением:
int MPI_Alltoallv(void *sendbuf, int *sendcounts,
int *sdispls, MPI_Datatype sendtype,
void *rcvbuf, int *rcvcounts, int *rdispls,
MPI_Datatype rcvtype, MPI_Comm comm)
Ее параметры аналогичны параметрам подпрограммы MPI_Alltoall, кроме двух дополнительных параметров:
· sdispls — целочисленный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент jзадает смещение относительно начала буфера, из которого данные передаются j-му процессу.
· rdispls — целочисленный массив, количество элементов в котором равно количеству процессов в коммуникаторе. Элемент i задает смещение относительно начала буфера, в который принимается сообщение от i-го процесса.
Операции приведения и сканирования относятся к категории глобальных вычислений. В глобальной операции приведения к данным от всех процессов из заданного коммуникатора применяется операция MPI_Reduce (рис. 6.5).
Аргументом операции приведения является массив данных — по одному элементу от каждого процесса. Результат такой операции — единственное значение (поэтому она и называется операцией приведения).
В подпрограммах глобальных вычислений функция, передаваемая в подпрограмму, может быть: предопределенной функцией MPI, например MPI_SUM, пользовательской функцией, а также обработчиком для пользовательской функции, который создается подпрограммой MPI_Op_create.
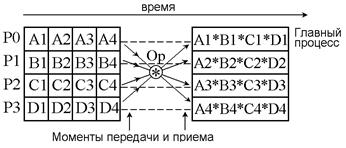 |
Рисунок 6.5.Глобальная операция приведения
Три версии операции приведения возвращают результат:
· одному процессу;
· всем процессам;
· распределяют вектор результатов между всеми процессами.
Операция приведения, результат которой передается одному процессу, выполняется при вызове подпрограммы MPI_Reduce:
int MPI_Reduce(void *buf, void *result,
int count, MPI_Datatype datatype,
MPI_Op op, int root, MPI_Comm comm)
Входные параметры подпрограммы MPI_Reduce:
· buf — адрес буфера передачи;
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.