Z-образ речевого сигнала S(Z)=V(Z)*H(Z) V(Z)-сигнал возбуждения
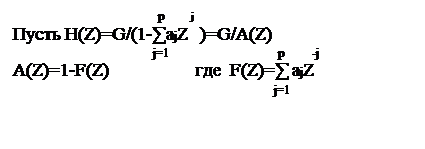
Отметим, что F(Z)-передаточная функция КИХ фильтра порядка p с линейным предсказанием.

y(n)=a1x(n-1)+a2x(n-2)+….+apx(n-p) ≈ x(n)
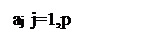 Предполагается что коэффициенты
Предполагается что коэффициенты ![]()
подбираются таким образом, чтобы обеспечить прогноз на один период дискретизации с наименьшей погрешностью. Поэтому данный метод и называют кодированием с линейным предсказанием.
При этом речевой сигнал S(n) восстанавливается на приемной стороне по следующему выражению:
Таким образом, синтезирующий фильтр является БИХ фильтром порядка p.
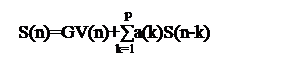
Метод “анализа через синтез”.
Общая идея заключается в следующем:
Новый подход использует процедуру оптимизации типа замкнутая петля, для нахождения возбуждающего сигнала V(n), которая подается на вход моделирующего фильтра синтезатора и создает оптимальный речевой сигнал при этом скорость передачи может быть понижена до 4,8 кбит/с.
Базовая структура системы кодирования включает в себя следующие блоки:
-анализатор формирующий с помощью LPC фильтра первый остаток
сигнала предсказания ε1(n)
-Возбуждающий генератор обеспечивающий генерацию вторичного возбуждения V2(n)
-Тоновый синтезирующий фильтр, выполняющий долгосрочное предсказание для вокализованных звуков
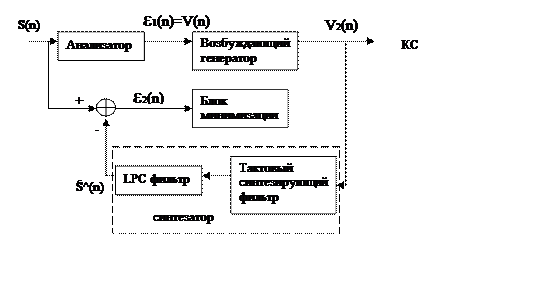
-LPC фильтр синтезатора синтезирующий оценку речевого сигнала
S^(n)
-Блок минимизации ошибки ε2(n)=S(n)-S^(n)
Алгоритм работы системы включает следующие операции:
1.Текущий кадр выборок речевого сигнала S(n) заносятся в буфер и с использованием фильтра с линейным предсказанием формируется LPC-коэффициенты.
2.Используется вычислительные LPC коэффициенты формируются остаток предсказания ε1(n) которая подается на возбуждающий генератор.
3.При генерации вторичного возбуждения V2(n) текущий кадр разбивается на подкадры для каждого подкадры для каждого подкадра:
а)рассчитываются параметры тонового синтезирующего фильтра, такие как, задержка и масштабирующий множитель, а также параметры LPC синтезир. фильтра.
б)определяются наилучшие вторичные возбуждения V2(n),
которые минимизируют ошибку ε2(n).
4.Окончательное синтезирование на передающей стороне производится путем пропускания вторичного кадра возб., через каскадно соединенные тоновый и LPC фильтры.
5.Шаги с 1 по 4 повторяются для следующего кадра
последовательности.
Принципиальное отличие данного метода от классических вокодеров, состоит в том, что в данном случае, возбуждение не разделяется на вокализованные и не вокализованные звуки, при этом сигнал возбуждения V2(n) может носить любой характер от псевдоимпульсного до шумоподобного.
Кодер стандарта G.723.1.
Оптимизирован для сжатия речи с высоким качеством на установленные скорости 5,3 и 6,3 кбит/с. Преобразует речь или другие аудио сигналы в кадры длительностью 50 мс.
Предназначен для работы с цифровыми сигналами, которые передаются по ТФ каналу при частоте дискретизации 8 кГц и разрядностью представления 16 бит. При этом текущий кадр разбивается на 4 подкадра по 60 выборок в каждом. Для каждого подкадра используется LPC фильтр 10-го порядка. Кроме того для каждых 2-х подкадров (120 выборок) вычисляется основного тона.
Новые методы кодирования с линейным предсказанием.
Известны следующие разновидности методов линейного предсказания.
1.С возбуждением от остатка RELP
2.С многоимпульсным возбуждением MPELP
3.С кодовым возбуждением (от кода) CELP
4.Вокодеры типа линейной спектральной пары LSP
Кодеры с возбуждением от остатка RELP.
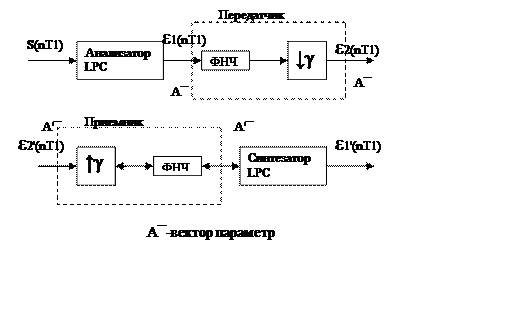
Остаток предсказания ε(nT1) пропускается через ФНЧ с полосой 800 Гц при передаче на скорости 9,6 кбит/с и 600 Гц на скорости 4,8 кбит/с. В первом случае сигнал остатка предсказания дискретизируется с частотой 7,2 кГц и с этой же частотой передачи в КС т.е. γ=1 остальные 2,4 кГц/с используется для передачи вектора LPC параметров А¯.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.