Даже точная идентификация ведёт к ухудшению качества, т.к. приводит к резким изменениям уровня фонового шума. Способом устранения этого является генерация комфортного шума.
Основным элементом DTX является детектор активности речи VAD. Реализация алгоритмов VAD базируется на положениях:
1)Речь – нестационарный сигнал. Форма её спектра обычно меняется через 20-30мс.
2)Фоновый шум обычно стационарен на более длинном отрезке времени, немного изменяясь.
3)Уровень речевого сигнала обычно выше уровня фонового шума. В противном случае речь неразборчива.
Основной принцип VAD – сравнение с порогом, т.к. шумовая обстановка меняется, то порог должен быть адаптивным. Существуют приложения в которых уровень шума м.б. высок и быстро изменяться во времени, что делает неэффективным применение простого энергетического порога. В любом случае порог должен вычисляться исходя из анализа сегмента сигнала, на котором присутствует только шум. Для этого проверяются спектральные характеристики сигнала.
Структурная схема VAD с обработкой в частотной области, применяемая в GSM имеет вид:

Работа схемы основана на различии спектральных характеристик сигнала и шума. VAD определяет спектр отклонения входного воздействия от спектра фонового шума. Это осуществляется инверсным фильтром, коэффициенты которого устанавливаются применительно к воздействию на входе только фонового шума.
При наличии (речь+шум) инверсный фильтр осуществляет подавление компонент шума и снижает его мощность. Далее сигнал подвергается пороговой обработке. Превышение порога сигнализирует о наличии речевой активности
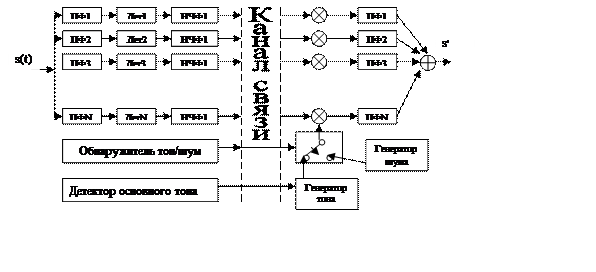
Передача Прием
При цифровой
реализации функции полосовой фильтрации детектирования и ФНЧ совмещается в
единой структуре многоканального цифрового фильтра демодулятора, на передающей
стороне и многоканального фильтра модулятора на приемной стороне. 
При первичном кодировании звукового сигнала в каналах студийного качества обычно требуется частота дискретизации fкв = 48 кГц (полоса 20..20000 Гц), разрядность представления – 16 бит. Т.о. скорость цифрового потока данных по одному каналу 768 кбит/с. С учетом дополнительных каналов стереофоническая передача может потребовать 3,84 Мбит/с. Установлено, что человек способен своими органами чувств сознательно обрабатывать потоки со скоростью 100 бит/с.
Различают статическую и психоакустическую избыточность. Сокращение первой базируется на учете статистических свойств звукового сигнала, а сокращение второй – на учете свойств звукового восприятия.
Статистическая избыточность обусловлена наличием корреляционной связи между соседними отсчетами звукового сигнала. Дополнительно уменьшить скорость цифрового потока позволяют методы кодирования, учитывающие статистику звукового сигнала с позиций вероятности появления различных уровней сигнала. Примером являются коды Хаффмана (наиболее вероятным значениям сигнала приписывается более короткие кодовые слова, а значениям отсчетов, вероятность появления которых мала – кодовые слова большой длины. Но при этом достижимая степень сжатия от 4 до 7 разрядов. Поэтому перспективными являются методы, учитывающие свойства слуха: маскировка, предмаскировка и послемаскировка. При этом, если известно, какие части звукового сигнала ухо воспринимает, а какие нет вследствии маскировки, можно передать лишь те части сигнала, которые ухо способно принять. Сигналы можно квантовать с меньшим разрешением по уровню таким образом, чтобы искажения квантования оставались неслышными, т.е. маскировались.
В основе разработки рекомендаций по аудио- и видеокодекам лежат рекомендации, разработанные экспертной группой MPEG. В 1992 г. был разработан международный стандарт MPEG-1. В настоящее время используются MPEG-2, MPEG-4. В качестве альтернативы в США был разработан стандарт Dolby AC-3.
Алгоритмы компрессии аудиоданных:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.