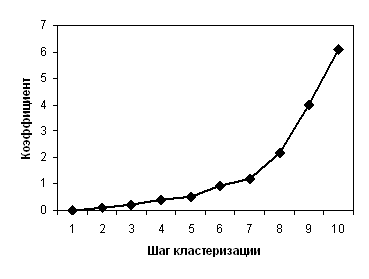
Рис. 8. Зависимость величины коэффициента от шага кластеризации
Рис. 9, б аналогичен, но элемент 5 дальше от расположенных близко друг к другу элементов 2 и 4. Поэтому вопрос о том, включать ли элемент 5 в кластер 2—4, или выделять его в отдельный кластер, требует дополнительного исследования другими методами. Но все же большую часть работы кластерный анализ сделал: другие элементы нашли свои места
Рис. 9, в показывает ситуацию, когда элементы 1 и 3 расположены рядом, элемент 2 близок к элементу 4, но элемент 5 расположен далеко от всех других. Таким образом, видны три кластера.
Наконец, рис. 9, г не показывает наличия компактных групп: элементы 1 и 3 близки, чуть дальше от них расположен элемент 2, еще чуть дальше от всех рассмотренных элементов находится элемент 4. Наконец, элемент 5 стоит особняком от всех других. В этом случае количество кластеров может определяться такими соображениями как количество сегментов, с которыми может работать организация. Если их, например, три, то выбирается такой уровень на дендрограмме, на котором имеются 3 ветви (показан пунктиром). Тогда первый кластер будет представлен элементами 1, 2 и 3, второй – 4, третий – 5.
Найдите на дендрограмме рис. 7 три кластера, которые были видны на рис. 5.
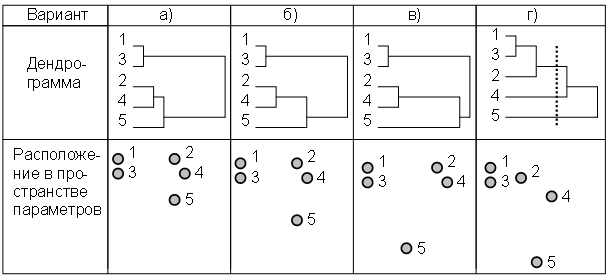 Рис.
9. Основные виды
дендрограмм
Рис.
9. Основные виды
дендрограмм
В файле Internet.sav, кроме информации о цене и наведенной известности присутствуют еще несколько переменных, Они описаны в табл. П.5. Переменные, выделенные курсивом, вычисляются по значениям других переменных этой же таблицы.
Цель анализа состоит в том, чтобы обнаружить группы организаций, близких по своим качествам.
1. Проведите иерархический кластерный анализ аналогично предыдущему случаю, задав следующие измененные параметры:
переменные для кластеризации – начиная c Price и заканчивая Seychas;
вывод только таблицы хода кластеризации (Agglomeration table);
вывод диаграмм (флажок Plots) снимается.
Не забудьте провести стандартизацию переменных.
2. Определите, после какого шага происходит значительное (более чем на 3 единицы) увеличение коэффициента, определите количество кластеров для этого шага. Убедитесь в том, что и в этом случае целесообразно выделить три кластера.
3. Выведите таблицу принадлежности элементов к кластерам. Для этого:
вновь начните иерархический кластерный анализ;
в окне Hierarchical cluster analysis щёлкните по кнопке Statistics... В рамке Cluster Membership (принадлежность к кластеру) активируйте радиокнопку Single solution (одно решение) и укажите в расположенном рядом поле Сlusters желаемое количество кластеров: 3;
задайте режим сохранения информации о принадлежности к кластерам в таблице исходных данных, для чего, щелкнув по кнопке Save… (сохранить), в рамке Cluster membership появившегося окна установите радиокнопку Single solution и значение 3 clusters;
запустите кластерный анализ кнопкой OK.
4. Изучите информацию о принадлежности организации к кластерам по таблице Cluster Membership и по значениям новой переменной clu3_1 в таблице данных. Перечислите организации, относящиеся к каждому из трех кластеров.
5. Определите профили найденных кластеров, для чего требуется рассчитать средние значения переменных, использованных в анализе, по кластерной принадлежности. Для этого:
выберите Analyze à Compare Means à Means (Анализ à Сравнить средние значения à Средние значения).
переменные 1-7 переместите в окно Dependent List: (список зависимых переменных), а переменную clu3_1 – в окно Independent List: (список независимых переменных)[19];
щелкнув по кнопке Options… оставьте в поле Cell Statistics (статистики для ячеек) только опцию Means (средние значения);
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.