|
XТ |
|||||||||
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
8 |
11 |
12 |
9 |
8 |
8 |
9 |
9 |
8 |
12 |
|
5 |
8 |
8 |
5 |
7 |
8 |
6 |
4 |
4 |
7 |
Обчислимо добутки матриць XТХ та XТY (функція Excel МУМНОЖ(<матриця 1>;< матриця 2>).
|
XТ |
XТY |
|||
|
10 |
94 |
62 |
72 |
|
|
94 |
908 |
595 |
710 |
|
|
62 |
595 |
408 |
474 |
|
Знайдемо обернену матрицю (XТХ)-1 (функція Excel МОБР(<діапазон>)). А потім обчислимо добуток матриць (XТХ)-1(XТY).
|
(XТ)-1 |
(XТХ)-1(XТY) |
|||
|
3,849883 |
-0,34239 |
-0,08571 |
а0 = |
-6,53302 |
|
-0,34239 |
0,055269 |
-0,02857 |
а1 = |
1,04637 |
|
-0,08571 |
-0,02857 |
0,057143 |
а2 = |
0,628571 |
За значеннями обчислених параметрів записуємо рівняння регресії y= -6,533+ 1,046x1+ 0,6286x2.
3 Використовуючи функцію ЛИНЕЙН, перевіряємо обчислення. Отримуємо такі дані:
|
0,6286 |
1,046 |
-6,533 |
|
0,1693 |
0,166 |
1,3897 |
|
0,9368 |
0,708 |
|
|
51,910 |
7 |
|
|
52,088 |
3,5119 |
Як бачимо з таблиці a0 = -6,533, a1 = 1,046, a2 = 0,6286, R2= 0,9368, Fp= 51,910.
Одержуємо рівняння регресії y= -6,533+ 1,046x1+ 0,6286x2.
Воно показує, що при збільшенні тільки потужності шару x1 (при незмінномуx2) на 1 м видобуток вугілля на одного робітника y збільшиться в середньому на 1,046 т, а при збільшенні тільки рівня механізації робіт x2 (при незмінномуx1) на 1% – у середньому на 0,6286 т.
4 Установимо значущість коефіцієнтів лінійної регресії. Обчислимо критеріальні значення tai = ai /σai.
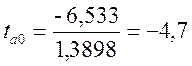
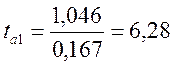

Задамо
рівень значущості ![]() та обчислимо критичне
значення
та обчислимо критичне
значення ![]() , де k – кількість
параметрів регресії; n – кількість вимірювань.
, де k – кількість
параметрів регресії; n – кількість вимірювань.
tkp=СТЬЮДРАСПОБР(0,05;7)=2,365
Якщо |tai | < tkr – коефіцієнти статистично не значущі, у випадку |tai |> tkr – коефіцієнти статистично значущі.
Висновок: коефіцієнти регресії а0 , а1, а2 статистично значущі.
5 Перевіримо якість моделі. Коефіцієнт детермінації R2=0,936,
скоригований коефіцієнт детермінації – =0,9188,
що свідчить про прийнятну якість моделі.
=0,9188,
що свідчить про прийнятну якість моделі.
6 Перевіримо адекватність моделі за критерієм Фішера.
Fp=51,91, Fkp=FРАСПОБР(0,05; 2; 7)=19,35.
Як бачимо Fp > Fkp, отже модель адекватна.
Висновок: модель Y= -6,533+ 1,046x1+ 0,6286x2 +U якісна і адекватна.
Нехай відібрана множина факторів х1,х2,...,хр, які впливають на досліджуваний показник Y. Є два протилежних критерії для вибору кінцевої моделі регресійного аналізу.
1 Якщо ми хочемо зробити модель корисною для прогнозу, то ми повинні включити якнайбільше факторів для того, щоб значення прогнозованої величини було надійним.
2 Оскільки одержання інформації з послідовним контролем при збільшенні кількості змінних має потребу в більших витратах, варто прагнути, щоб модель включала по можливості менше факторів.
Компромісом між цими крайностями є те, що називають вибором "найкращого" рівняння регресії. Для реалізації такого вибору немає єдиної статистичної процедури. Взагалі ж існує досить велика кількість методів побудови регресійної моделі, найбільш відомими є:
1) метод всіх можливих регресій;
2) метод виключень;
3) кроковий регресійний аналіз;
4) деякі модифікації попередніх методів та ін.
Ми розглянемо лише найпоширеніші на практиці методи побудови лінійних регресійних моделей.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.