 |
 |
 |
|||||||||||
ДОМЕНЫ
2. 8. 9. Построение модели хранилища средствами ERD
Построение модели ведется в следующей последовательности:
1) проводится идентификация сущностей, атрибутов и ключей,
2) проводится идентификация отношений между сущностями и определяется их значение,
3) проводится разрешение недопустимых отношений n:m.
1. Идентификация сущностей, атрибутов и ключей
Идентификация проводится на основе анализа хранилищ и сравнение входных и выходных потоков данных.
В качестве примера рассмотрим базу данных бухгалтера, содержащую данные о персонале. Хранилище имеет следующие входные и выходные потоки:
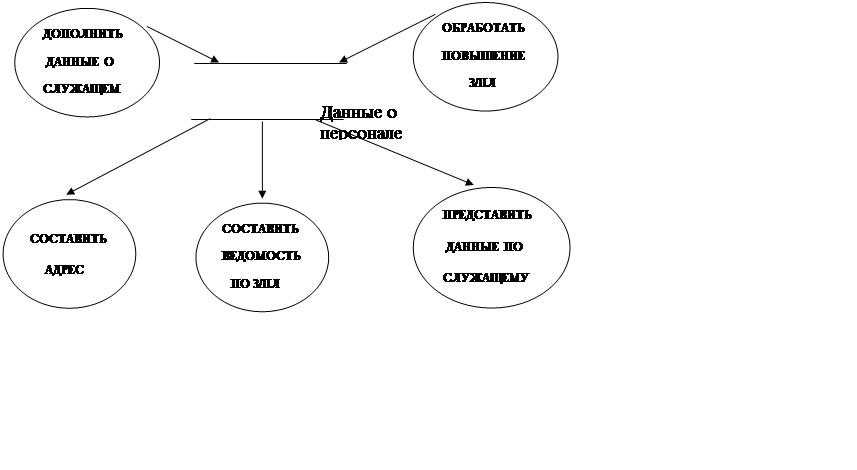 |
НАЕМ, УВОЛЬНЕНИЕ ИЗМЕНЕНИЕ В З/ПЛ
АДРЕСА СЛУЖАЩИХ ИСТОРИЯ ЗАНЯТОСТИ
ПОДРОБНОСТИ З/ПЛ
Описание и сравнение входных и выходных потоков данных
В рассматриваемом примере структура данных имеет вид:
ВНОВЬ_НАНЯТЫЕ АДРЕС_СЛУЖАЩЕГО
Дата_найма фамилия
фамилия адрес
таб_номер ПОДРОБНОСТИ_З/ПЛ
адрес фамилия
должность таб_номер
начальная_з/пл текущая_з/пл
УВОЛЕННЫЕ ИСТОРИЯ_ЗАНЯТОСТИ
фамилия фамилия
таб_номер таб_номер
ИЗМЕНЕНИЕ_АДРЕСА дата_найма
фамилия ИСТОРИЯ_КАРЬЕРЫ
таб_номер должность
старый_адрес дата_изменения
новый_адрес ИСТОРИЯ_З/ПЛ
ИЗМЕНЕНИЕ_З/ПЛ з/пл
фамилия дата_изменения
таб_номер
старая_з/пл
новая_з/пл
дата_изменения
На основании анализа данных выявляется, какие данные необходимо хранить в хранилище, чтобы они удовлетворяли входным и выходным потокам. Так, нет необходимости в хранилище только предыдущей (старой) з/пл. Для сущности ИСТОРИЯ_З/ПЛ необходимо иметь всю последовательность изменения з/пл. Также не нужен старый адрес и нет необходимости в сущности ПОДРОБНОСТИ_З/ПЛ, если есть ИСТОРИЯ_З/ПЛ.
В результате такого анализа структура хранилища примет вид:
фамилия ИСТОРИЯ_КАРЬЕРЫ
таб_номер должность
адрес дата_изменения
текущая_з/пл ИСТОРИЯ_З/ПЛ
дата_изменения
На следующем шаге выполняется упрощение структуры (устранение избыточности).
Из рассмотренной выше структуры в качестве избыточных данных можно убрать текущая_з/пл, т.к. она определяется последним состоянием з/пл и указывается в ИСТОРИЯ_З/ПЛ. Можно убрать дата_найма, т.к. это данное определяется первой записью в ИСТОРИЯ_КАРЬЕРЫ или в ИСТОРИЯ_З/ПЛ. Можно убрать дата_изменения в ИСТОРИЯ_КАРЬЕРЫ, т.к. она обычно совпадает с дата_изменения в ИСТОРИЯ_З/ПЛ. Можно объединить ИСТОРИЯ_З/ПЛ и ИСТОРИЯ_КАРЬЕРЫ в виде ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ. В результате получим структуру:
фамилия
таб_номер
адрес
ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ
должность
дата_изменения
Далее проводятся дальнейшие упрощения в виде нормализации. Для этого данные делятся на две группы и в них выделяется общий ключевой атрибут. Так в рассматриваемом случае:
- неизменные данные
![]() фамилия
фамилия
адрес СОТРУДНИК,
таб_номер
- изменяющиеся данные
![]() з/пл
з/пл
должность ИСТОРИЯ_З/ПЛ_КАРЬЕРЫ.
дата_изменения
Затем в группах выделяются ключевые атрибуты.
В рассматриваемом примере в каждой группе за ключевой атрибут необходимо взять таб_номер. В результате структура данных представится в виде двух файлов:
|
|
||||
![]()
![]()
2. Определение отношений между сущностями
На этом этапе между выше определенными сущностями устанавливаются связи и отношения. Кроме того, определяются отношения с окружающими сущностями.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.