|
Группа |
Среднее значение возраста |
Стандар. откл-е |
Кол-во объектов |
Стандартная ошибка среднего |
Расчет 95% ДИ среднего |
|
м |
43,05 |
17,27 |
449 (21,19) |
17,27/ sqrt (449) |
(2*0,815) = 1,63 +(-) |
|
ж |
45,80 |
16,83 |
726 (26,94) |
- |
1,25 +(-) |
Таблица 4 Пример расчет 95% интервала значений признака
|
Группа |
Среднее значение возраста |
Стандар. откл-е |
Расчет границ 95% интервала значений |
Нижняя граница |
Верхняя граница |
|
м |
43,05 |
17,27 |
(+/-)2*17,2 = 34,54 |
8,51 |
77,59 |
|
ж |
45,80 |
16,83 |
(+/-) 2*16,83 |
12,14 |
79,46 |
Таблица 5. Тест Колмогорова-Смирнова: проверка нормальности выборочного распределения признака «возраст» (TestsofNormality)
|
Пол |
Kolmogorov-Smirnov |
||
|
значение статистики Statistic |
степень свободы df |
эмпирический уровень значимости Sig. |
|
|
м |
0,096 |
449 |
0,000 |
|
ж |
0,085 |
726 |
0,000 |
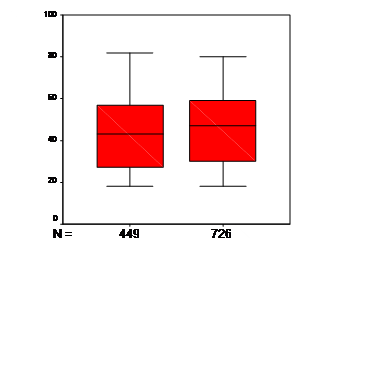
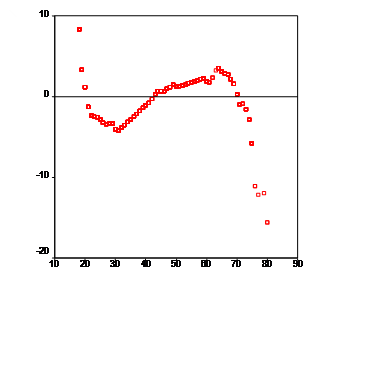
Рис.1Ящичковая диаграммаРис. 2График Q-Q с исключенным трендом
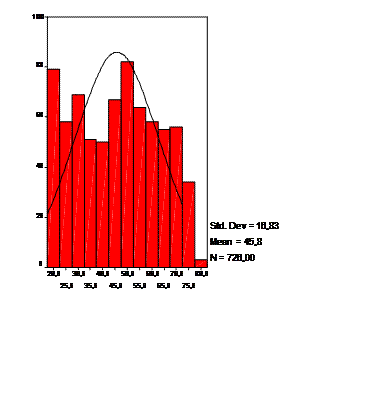
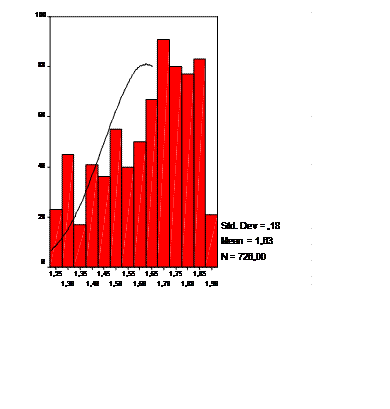 признака «возраст» в группе женщин
признака «возраст» в группе женщин
Рис.3Гистограмма распределения Рис. 4 Гистограмма распределения натурального возраста в группе женщин (с наложением логарифма возраста в группе женщин кривой нормального распределения) (с наложением кривой нормального распределения)
(Процедура DATA)
Меню DATA содержит различные возможности для преобразования массива данных. На практике часто используется процедура агрегирования данных, заключающаяся в укрупнении объектов анализа. Последовательность шагов этого процесса представлена на рис. 1 – 4.
В табл. 1 отражены результаты «ремонта выборки» с помощью весовых коэффициентов.
(Aggregate)
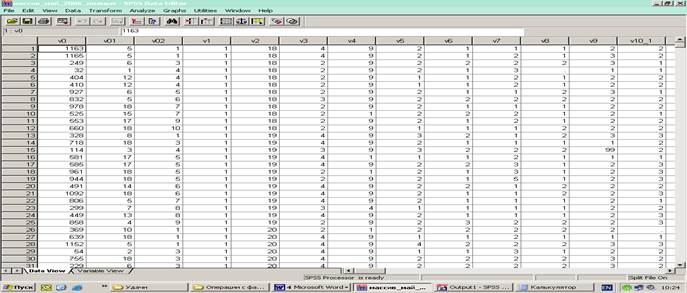
Рис. 1 Исходный массив (объекты – респонденты)
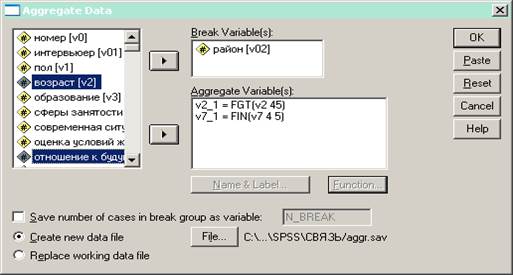
Рис. 2 Процедура Aggregate
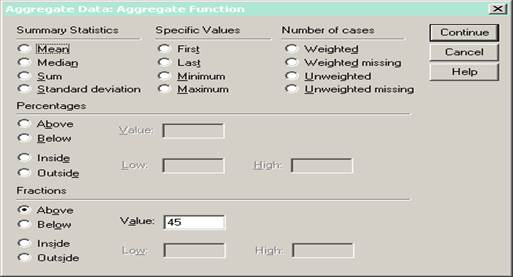
Рис. 3 Создание новых (агрегированных) переменных
Per. above – процент объектов, у которых переменная принимает значения большие указанного (включительно).
Per. below – процент объектов, у которых переменная принимает значения меньшие указанного (включительно).
Frac. above – доля объектов, у которых переменная принимает значения большие указанного (включительно).
Frac. below – доля объектов, у которых переменная принимает значения меньшие указанного (включительно).
Per. inside – процент объектов, у которых значение переменной находится в указанном интервале (интервал закрытый).

Рис. 4. Агрегированный массив данных
(Weight cases)
Таблица 1. Структура выборки до и после взвешивания
|
Район |
Структура до взвешивания |
Структура генеральной совокупности |
Весовой коэффициент |
Структура после взвешивания |
|
Дзержинский |
10,2 |
11,0 |
1,1 |
11,3 |
|
Железнодорожный |
8,0 |
4,4 |
0,6 |
4,8 |
|
Заельцовский |
10,4 |
9,7 |
0,9 |
9,4 |
|
Калининский |
10,0 |
12,2 |
1,2 |
12,0 |
|
Кировский |
10,0 |
11,9 |
1,2 |
12,0 |
|
Ленинский |
14,7 |
19,2 |
1,3 |
19,3 |
|
Октябрьский |
10,0 |
12,4 |
1,2 |
12,0 |
|
Первомайский |
8,4 |
5,0 |
0,6 |
5,1 |
|
Советский |
9,7 |
9,2 |
0,9 |
8,8 |
|
Центральный |
8,7 |
5,1 |
0,6 |
5,2 |
|
ВСЕГО |
100,0 |
100,0 |
- |
100,0 |
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.