Рисунок 4.3 Высокоуровневый вид путей данных подготовленной последовательной DLX
Таблица 4.3 Входы и выходы путей данных на каждом этапе kподготовленной DLX
|
stage |
in(k) |
out(k) |
|
|
0 |
IF |
DPC, IM |
IR |
|
1 |
ID |
GPR, PC', IR |
A, B, PC', link, DPC, со, Cad.2 |
|
2 |
EX |
A, B, link, со, Cad.2, IR |
MAR, MDRw, Cad.3 |
|
3 |
M |
MAR, MDRw, DM, Cad.3, IR |
DM, C, MDRr, Cad.4 |
|
4 |
WB |
C, MDRr, Cad.4, IR |
GPR |
время цикла, поскольку только последние два бита адреса влияют на расстояние сдвига, а эти биты известны в начале цикла. Обычно память Mразбита на память команд IMи память данных DM.
Есть, однако, простое но глобальное изменение, в котором мы синхронизируем выходные регистры этапов. Вместо единственного сигнала разрешения обновления UE(раздел 3.4.3), мы вводим для каждого этапа kсигнал четкого разрешения обновления ue.k. Выходной регистр Rэтапа kмодифицируется тогда и только тогда, когда и сигнал запроса синхронизации
|
|
Рисунок 4.4 Управление обновлением выходных регистров этапа k
Rceи сигнал разрешения обновления на этапе kактивны (рисунок 4.4). Таким образом, сигнал разрешения синхронизации Rce' такого регистра Rполучается как
Rce' = Rcе /\ ue.k.
Как и прежде, сигналы чтения и записи основной памяти Mне маскируются сигналом разрешения обновления ue.3 но заполняют бит full.3 этапа памяти.
4.2.1 Пути данных подготовленной DLX
Окружение IRenv
регистра команд все еще управляется сигналами Jjump(J-type jump), shiftIи синхронизирующим сигналом IRce. Функциональные возможности фактически те же самые, что и прежде. При IRce = 1, выход IMoutпамяти команд синхронизируется с регистром команд
IR= IMout,
и 32-битной константа со генерируется как в последовательной конструкции, а именно
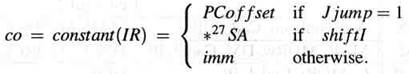
Стоимость и задержка окружения IRenv остаются теми же.
Для использования в дальнейших конвейерных этапах, два кода операций IR[31 : 26] и IR[5 : 0] буферизируются в трех регистрах
IR .k, каждый из которых шириной в 12 бит.
Окружение SH4Lenv
управляется сигналом shift4l, который запрашивает сдвиг в случае загрузки команды. Единственное изменение в этом окружении то, что адрес памяти теперь предоставляется регистром С а не регистром MAR. Это влияет на функциональность окружения SH4Lenv, но не на стоимость и задержку.
Пусть sh4l(a, dist) означает функцию, вычисляемую устройством сдвига SH4L, как это было определено в разделе 3.3.7. Тогда измененное окружение SH4Lenv обеспечивает результат
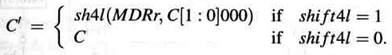
Окружения CAddr и GPRenv
Как в последовательной конструкции, схема CAddrгенерирует адрес Cadрегистра назначения основываясь на сигналах Jlink(jump и link) и Itype. Однако, адрес Cadтеперь заранее вычисляется на этапе ID и затем проходит вниз этап за этапом к окружению файла регистров GPRenv. Для дальнейшего использования, мы вводим запись
Cad = CAddr(IR).
Окружение GPRenv (рисунок 4.5) имеет те же самые функциональные возможности. Оно обеспечивает два регистровых операнда
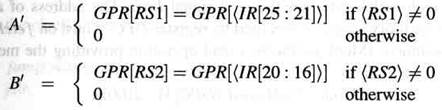
и обновление файла регистров под управлением сигнала записи GPRw:
GPR[Cad.4]=C' если GPRw=1.
Так как схема CAddrтеперь имеет свое собственное окружение, стоимость окружения файла регистров GPRenv равна
CGPRenv = Cram3(32,32)+2* (Czero(5) + Cinv + Cand(32)).
Из-за вычисляемого заранее адреса назначения Cad.4 обновление файла регистров становится быстрее. Окружение GPRenv теперь задерживает только доступ по записи
DGPR,write = Dram3(32,32).
Пусть Acon(csWB) означает накопленную задержку управляющих сигналов которые управляют этапом WB; время цикла этапа обратной записи равно
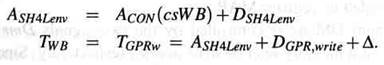
Задержка DGPR,readдоступа по чтению, однако, остается неизменной; она складывается со временем цикла этапа IF и блока управления.
|
|
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.

