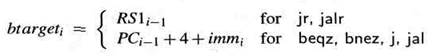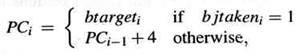Основы конвейеризации
В CPU, сконструированном в предыдущей главе, команды DLX выполняются последовательно; это значит, что выполнение команды начинается только после того, как закончено выполнение предыдущей команды. Выполнение команды занимает от 3 до 5 тактов. Большая часть аппаратных средств CPU неактивно большую часть времени. Следовательно, попытаемся переопределить использование аппаратных ресурсов так, чтобы одновременно смогли выполняться несколько команд. Очевидно, должны выполняться следующие условия:
1. Не должны существовать структурные опасности (structuralhazards), т.е., одновременное использование одного аппаратного ресурса двумя командами.
2. Машина должна быть корректна, т.е. аппаратные средства должны интерпретировать набор команд.
Простейшим является такое определение основной конвейеризации (basicpipelining): выполнение каждой из команд разбито на пять этапов k, перечисленных в таблице 4.1. Этапы IFи IDсоответствуют непосредственно состояниям fetch и decodeдиаграммы конечных состояний (FSD) на рисунке 3.20. На этапе Mвыполняется доступ команд к памяти по чтению и записи. На этапе WBрезультат пишется обратно в регистр общего назначения. Грубо говоря, все остальное выполняется на этапе EX. Рисунок 4.1 изображает возможное разбиение состояний FSD на эти пять этапов.
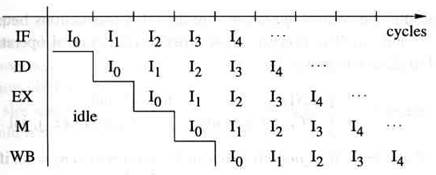
Мы рассматриваем выполнение последовательности I = I0, I1, ... команд DLX, где команде I0 предшествует reset. Для тактов Т = 0,1,...,
Таблица 4.1 Этапы выполнения конвейеризированных команд
|
k |
сокращение |
имя |
|
0 |
IF |
выборка команды |
|
1 |
ID |
декодирование |
|
2 |
EX |
выполнение |
|
3 4 |
M WB |
память запись обратно |
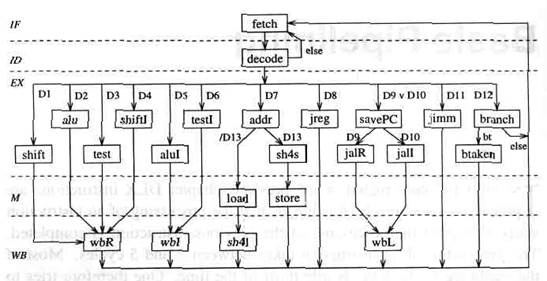
Рисунок 4.1 Разбиение FSD последовательной DLX на пять этапов согласно таблице 4.1.
состояния kи команды Ii, мы используем
I(k, T) = i
как сокращение для выражения того, что команда Ii находится на этапе kв течении цикла T. Выполнение начинается в цикле Т = 0 при I(0,0) = 0.
В идеале, мы хотели бы выбирать новую команду в каждом цикле и каждая команда должна выполняться за один этап в каждом цикле, т.е.,
• если I(0, Т) = i тогда I(0, T + 1) = i + 1,
• если I(k, T) = i и k< 4 тогда I(k+1, T + 1) = i.
Для всех этапов kи циклов Т мы имеем
I(k,T) = i <-> T = k + i
|
|
Рисунок 4.2 Конвейерное выполнение последовательности команд I0 , I1 , I2 , I3 , I4
Это идеальное определение изображено на рисунке 4.2. Очевидно, две команды никогда не находятся на одном этапе одновременно. Если мы сумеем распределить каждый аппаратный ресурс на этапе kтак, чтобы ресурс использовался только командой Ii пока Ii находится на этапе k, тогда один аппаратный ресурс никогда не будет использоваться двумя командами одновременно, таким образом избежав структурных опасностей.
Для сконструированной машины это пока что не может быть выполнено по двум причинам:
1. Сумматоры используются на этапе декодирования (decode) для приращения PC и на этапе выполнения (execute) для операций ALU или для вычисления адреса перехода. Команды jal и jalr используют сумматор на этапе выполнения дважды, а именно: для вычисления адреса и для пропуска (passing) PC в файл регистров. Таким образом, по крайней мере, мы должны обеспечить дополнительный сумматор для увеличения значения PCв течении этапа decodeи путь обхода ALU для сохранения PC.
2. Память используется на этапах выборки (fetch) и памяти (memory). Таким образом, должна быть обеспечена дополнительная память команд IM.
4.1 Задержанное Ветвление и Задержанный PC
Мы все еще не можем выбирать новую команду в каждом такте. Прежде чем мы объясним простую причину этого, введем несколько обозначений.
Для регистра Rи команды Ii мы обозначим через Ri содержимое регистра R после выполнения (последовательного) команды Ii. Обратите внимание, что команда Ii выбирается из памяти команд, адресуемой PCi-1. Обозначение может быть продлено на поля регистров. Например, immi означает содержимое непосредственного поля регистра команд IRi. Обозначение в дальнейшем может быть продлено на выражения, зависящие от регистров.
Повторимся, что управляющие операции есть команды DLX beqz, bnez, jr, jalr, j и jal. Адрес перехода btargetiуправляющей операции Ii определяется очевидным способом
|
|
Мы говорим, что branch (ветвление) или jump (переход) приняты в Ii, (короче bjtakeni= 1), если
• Ii типа j, jal, jr или jalr, или
• Ii ветвление beqz и RS1i = 0, или
• Ii ветвление bnez и RS1i =/= 0.
Сейчас предположим, что команда Ii является управляющей операцией выбранной в цикле T, где
Ii = IM[PCi-1].
Следующая команда Ii+1 должна быть выбрана из PCi
|
|
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.