Рисунок 4.17 Верхнеуровневые схемные решения путей данных DLXπс пересылкой. Ради ясности адресные и управляющие входы механизма пересылки опущены.
Реализация схемы Forw
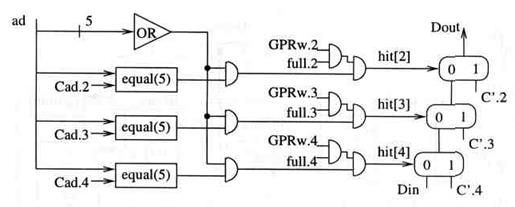
Пример реализации показан на рисунке 4.18. Схема слева генерирует три сигнала hit[4 : 2], тогда как фактически выбор данных осуществляется тремя мультиплексорами. Сигналы top.jподразумеваются в порядке мультиплексоров. Сигналы top.j, которые необходимы механизму пересылки, могут быть сгенерированы двумя инверторами и тремя вентилями AND. Стоимость этой реализации схемы Forwрассчитывается как
СForw(3) = 3 • (Cequal (5) + 3 • Cand + Cmux(32))
+Cortree (5) +2• Cinv + 3 • Cand.
Этот механизм пересылки предоставляет выход Doutи сигналы top.jсо следующими задержками
DForw(Dout;3) = Dequal(5) + 2*Dand + 3*Dmux DForw(top;3) = Dequal(5) + 4*Dand + 3*Dmux;
|
|
Рисунок 4.18 Реализация 3-х этапной схемы пересылки Forw(3)
задержка увеличивается из-за проверки адресов. Фактически данные Dinи C'.jзадерживаются не более чем на
DForw(Data;3) = 3*Dmux.
Пусть A(C', Din) означает накопленную задержку входов данных C'.iи Din. Так как адреса берутся непосредственно из регистров, механизм пересылки может предоставлять операнды Ainи Binс накопленной задержкой A(Ain,Bin); эта задержка воздействует только на время цикла этапа ID.
A(C',Din) = max{AEXenv ,ASH4Lenv ,DGPR ,read}
A(Ain,Bin) = max{A(C',Din)+AForw(Data,3),DForw(Dout,3)}
Очевидно, конструкция обобщена для s-этапной пересылки с s> 3, но тогда задержка пропорциональна s. Основываясь на параллельных префиксных схемах можно сконструировать схемы пересылки Forw(s) с задержкой O(log s) (см. упражнение 4.3).
4.4.3 Корректность
|
Iπ (k,T) = 1. В течении этого цикла команда Ii-α находится на этапе 1 + α: Iπ (1 + αT) = I - α. |
Теперь мы переходим к доказательству теоремы 4.7. Мы начнем с простого наблюдения битов правильности в ситуации, когда команда Ii читает регистр GPR[r] и одну из трех предшествующих команд Ii-α (при a € {1,2,3}) записанную в регистр GPR[r]. В конвейерной машине чтение происходит в цикле Т, когда команда Ii находится на этапе 1, т.е., когда
Мы рассмотрим время T ', когда команда Ii-α находится на этапе 1 + α подготовленной последовательной машины:
Iσ(1 + αT' ) = I - α.
|
Предположим, что гипотеза теоремы 4.5 верна; Ii читает GPR[r], команда Ii-α пишет GPR[r], и Iα(1 + α, T’ ) = I - α, тогда C'.(l + α)T 'σ = GPR[r]i-α . |
|
Если Ii-a является командой загрузки, тогда по гипотезе теоремы мы имеем α = 3. В этом случае, биты правильности генерируются как v[4]i-α = v[1+α]i-α = 1. |
|
В других случаях сигналы правильности для любых j>= 2 равны |
|
v[j]i-α = l. |
|
Теперь требования следуют прямо из леммы 4.8. |
|
Доказательство теоремы 4.7 Доказательство выполняется теми же самыми строками, что и доказательство теоремы 4.5 индукцией по Tгде Tозначает цикл в конвейерном выполнении с In(k, T) = i. Так как были изменены только входы этапа 1, доказательство для случая T = 0 и шаг индукции для k =/= 1 остаются буквально теми же самыми. Кроме того, в шаге индукции, когда мы решаем от T — 1 до Tдля k = 1, мы уже можем принять теорему для Tи k > 1. Нам необходимо показать требование только для тех входных сигналов этапа 1, которые зависят от результатов более поздних стадий, т.е., сигналов Ainи Bin. Для всех других сигналов и выходных регистров этапа 1, требование может быть заключено как в доказательстве теоремы 4.5. Чтение из GPR[r] может производиться в регистр Aили в регистр B. В шаге индукции мы обрабатываем только тот случай, когда команда Ii читает GPR[r] в регистр A. Чтение в регистр В обрабатывается таким же образом с очевидными исправлениями записей. Существует два случая. В интересном случае гипотеза теоремы 4.5 не верна для команды Ii, т.е., существует α € {1,2,3} такое, что команда Ii-α пишет GPR[r]. По гипотезе теоремы эта команда не является командой загрузки. Для битов правильности это подразумевает |
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.