Так как DPCi-1 = PCi-1 то при задержке ветвления и задержке PC выбирается одна и та же команда Iiи в обоих случаях переменная bjtakeniимеет одинаковое значение.
Если bjtakeni = 0, тогда
pc'i = PCi-1 + 4
= PCi + 4 по индукционной гипотезе
= PCi+1 по определению задержанного ветвления.
Если bjtakeni = 1, тогда команда Ii не может занять слот задержки и, следовательно, bjtakeni-1 = 0. Если Ii типа beqz, bnez, j или jal, тогда
PC'i = PC'i-1 + immi
= PCi-2 + 4 + imm, поскольку bjtakeni-1 = 0
= PCi-1 + 4 + imm, по гипотезе для i - 2
= btargeti
= PCi+1 поскольку bjtakeni = 1.
Если Ii типа jr или jalr, тогда
pc'i = RS1i-1
= btargeti
= PCi+1 поскольку bjtakeni = 1,
и первая часть гипотезы доказана.
Для второй части предположим что Ii является командой перехода или связи. Тогда при задержанном ветвлении сохраняется PCi-1 + 8. Поскольку Ii не в слоте задержки, мы имеем
PCi-1 + 8 = PCi + 4
= DPCi + 4 по индукционной гипотезе
= PC'i-1 + 4 по определению задержанного PC.
|
QED |
Это соответствует значению, сохраняемому в версии с задержанным PC.
Таблица 4.2 иллюстрирует для обоих механизмов, задержанного ветвления и задержанного PC, как обновляются PC в случае команд перехода и связи.
4.2 Подготовленные последовательные машины
В этом разделе мы сконструируем машину DLXσсо следующими свойствами:
1. Машина состоит из путей данных, управления а также механизма останова для генерации синхроимпульсов.
Таблица 4.2 Влияние команд перехода и связи Ii € {jal, jalr} на PC в режиме задержки ветвлений и задержки PC
|
after |
delayed branch |
delayed PC |
|||
|
PC |
GPR[31] |
DPC | PC' |
GPR[31] |
||
|
Ii-1 |
PCi-1 |
PCi-1 |
PCi-=PCi-1+4 |
||
|
Ii |
PCi-1+4 |
PCi-1+8 |
PC'i-1 = PCi |
PCi+1 = btargeti |
PC'i-1+4 |
|
Ii+1 |
btargeti |
PC'i = btargeti |
PCi+2 |
||
2. Пути данных и управление машины размещены в 5-ти этапном конвейере, но
3. Только один этап одновременно является синхронизируемым в round robin fashion. Таким образом, машина DLXσбудет последовательной; это легко подтверждается использованием методов предыдущей главы.
4. Машина может быть превращена в конвейерную машину DLXπтолько простейшим преобразованием окружения PCи механизма останова. Верность этого показывается моделирующей теоремой заявляющей – согласно некоторым гипотезам – что машина DLXπмоделирует машину DLXσ.
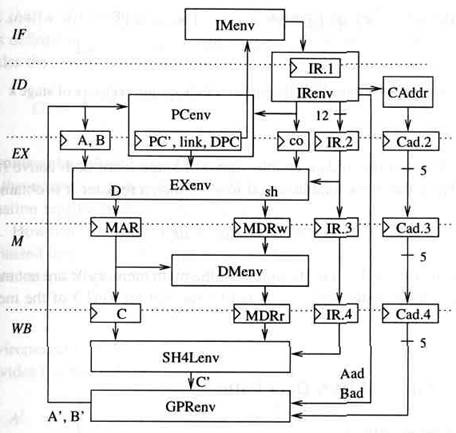
Мы назовем машину DLXσ подготовленной последовательной машиной. Полная структура путей данных изображена на рисунке 4.3. Есть 5 этапов регистров и ячеек RAM. Обратите внимание, что мы размещаем все регистры и ячейки RAM внизу этапа, где они вычисляются.
Для каждого этапа k – с номерами или именами из таблицы 4. 1 – мы обозначим через out(k) набор регистров и ячеек RAM вычисляемых на этапе k. Точно так же, мы обозначим через in(k) набор регистров и ячеек RAM которые являются входами этапа k. Эти наборы для всех k перечислены в таблице 4.3. R .kозначает, что Rявляется выходным регистром этапа k - 1, то есть, R. k€ out(k - 1).
Стоимость путей данных
cdp = CPCenv + CIMenv + CIRenv + CEXenv + CDMenv
+ CSH4Lenv + CGPRenv + CCAddr + 7*Cff(32) + 3 • Cff (5 +12).
Большинство окружений может быть взято из конструкции последовательной DLX. Только два окружения подвергаются изменениям: окружение PC и окружение выполнения EXenv. Окружение PC должно быть адаптировано для механизма задержки PC. Для команд хранения вычисление адреса в состоянии addrи сдвиг операнда в состоянии sh4sтеперь должны происходить в одном цикле. Это не будет значительно замедлять
|
|
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.