|
Рис. 8 Регресія y по x |
Рис. 9 Регресія x по y |
||
|
––○–– |
Емпірична лінія yx |
––○–– |
Емпірична лінія xy |
|
▬▬▬ |
Теоретична лінія |
▬▬▬ |
Теоретична лінія |
|
- - - - - |
Межі 95%-вої смуги |
- - - - - |
Межі 95%-вої смуги |
Мета цього розділу – допомогти студенту засвоїти методику обробки даних малої вибірки, або коли спостереження наведені в декількох повтореннях, але є невелика кількість різноманітних варіантів.
Продовжуємо аналіз прикладу, що розбирався послідовно протягом
попередніх чотирьох розділів. Суто формально ми зробили обробку наведених вище
даних (див. табл. 1) і переконалися в існуванні тісного і значущого
кореляційного зв'язку між обсягами прохідницьких робіт і собівартістю 1 т
вугілля, що добувається, причому більш тісною виявилася спряжена залежність  .
.
Як зазначалося вище, кореляційний аналіз не вирішує питання ані про природу досліджуваних зв’язків, ані про їхній напрямок – це справа фахівців. Але, на думку фахівців, між досліджуваними показниками взагалі не повинно бути ніяких зв’язків, тому що всі підготовчі роботи виконуються за рахунок капіталовкладень, і ці витрати не повинні враховуватися при розрахунку собівартості.
Як же пояснити отримані нами результати? (це є приклад змістовного аналізу, коли формальні статистичні процедури чергуються з неформальними висновками фахівців). Тут потрібне більш глибоке вивчення проблеми з урахуванням інших факторів, зокрема, мінливості даних за часом. Розглядаючи рис. 1 (продубльований нижче на рис. 10), зауважимо, що залежності між x і y за кожний конкретний рік дійсно немає, проте з року в рік зростала собівартість вугілля, а в останні два роки істотно зростали також і обсяги прохідницьких робіт.
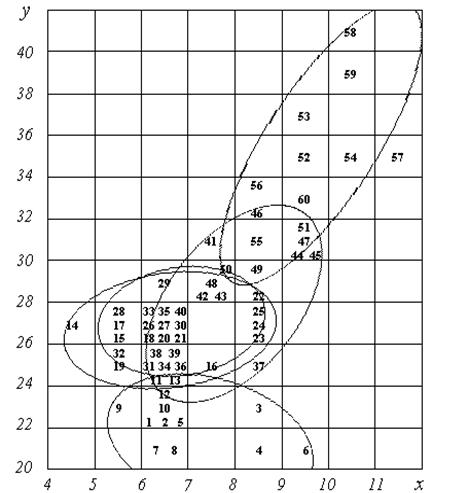
Рис. 10. Кореляційне поле
В останньому рядку табл. 1 наведені усереднені за кожний рік значення x і y. Ці середньорічні дані виписані в табл. 8 (перші 4 стовпчика). Якщо ми маємо у своєму розпорядженні тільки ці середньорічні значення, то маємо справу з малої (n=5) вибіркою. Насправді в нас є 12–разова повторність кожного показника x і y, але в табл. 8 наведено не всі спостереження, а лише середні за групами (за кожний рік); цілком же вихідні дані містяться в табл. 1. Для того, щоб переходячи від табл. 1 до табл. 8 не втратити істотну інформацію про мінливість даних, необхідно крім середніх по групах обчислити і зберегти суми квадратів відхилень у кожній групі.
Таблиця 8
Обробка середньорічних даних
|
n |
t |
x |
y |
T |
T2 |
xT |
yT |
x2 |
y2 |
|
1 |
1981 |
6,8 |
22,45 |
-2 |
4 |
-13,6 |
-44,90 |
46,24 |
504,00 |
|
2 |
1982 |
6,6 |
26,69 |
-1 |
1 |
-6,6 |
-26,69 |
43,56 |
712,36 |
|
3 |
1983 |
6,4 |
26,64 |
0 |
0 |
0 |
0 |
40,96 |
709,69 |
|
4 |
1984 |
7,9 |
28,70 |
1 |
1 |
7,9 |
28,70 |
62,41 |
823,69 |
|
5 |
1985 |
9,5 |
33,91 |
2 |
4 |
19,0 |
67,82 |
90,25 |
1149,89 |
|
Середні |
1983 |
7,44 |
27,68 |
0 |
2 |
1,34 |
4,99 |
56,68 |
779,93 |
Розглянемо спочатку особливості обробки малої вибірки, вважаючи, що в табл. 8 наведені всі дані. Оскільки цих даних небагато (усього п’ять), жодних угруповань не потрібно. Іноді можна обійтися і без переходу до умовних одиниць, зокрема, у даному прикладі залишимо незмінними значення змінних x і y. Проте, щоб не мати справи з великими числами, із усіх значень t віднімемо середнє: T = t - 1983 (бажано так робити з усіма змінними; замість точних середніх можна віднімати найбільш близькі до середнього значення з таблиці, зокрема, зручно прийняти X = x – 7,9 і Y = y – 28,7).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.