Так само робимо з іншою змінною: ymax=41,69 ; ymin=20,97 ; розмах D y=20,72 . При стандартної кількості класів ky=10 крок дорівнює hy=2,097 . Округляємо його до hy=2 . Нові границі: ymax=42 ; ymin=20 ; D y=42 ‑ 20=22 . Нове число класів: ky=Dy / hy=11.
Будуємо сітку розміром 8 ´11. Тепер послідовно переглядаємо спостереження табл. 1 і наносимо відповідні точки на кореляційне поле. Особливої точності при нанесенні точок не потрібно, тому що дані, що попадають в одну клітинку, будуть округлені на її центр. Точки, що попадають на границю класів, треба відносити до інтервалу з більшим номером (є і прямо протилежна рекомендація, але вона не узгоджується з прийнятим у нас визначенням функції розподілу випадкової величини).
На рис. 1 приведене побудоване таким чином кореляційне поле, причому замість звичайних точок виявилося можливим (через невеликий обсяг вибірки) поставити номери спостережень, що подає додаткову інформацію до міркування: на малюнку можна виділити області розкиду даних за кожний рік. У подальшому аналізі ми використаємо цю додаткову інформацію: у даних за п'ятирічний період чітко проглядається кореляційна залежність – загальне облако розсіювання витягнуте по діагоналі і видно, що більшим обсягам прохідницьких робіт відповідають у середньому більші значення собівартості продукції.
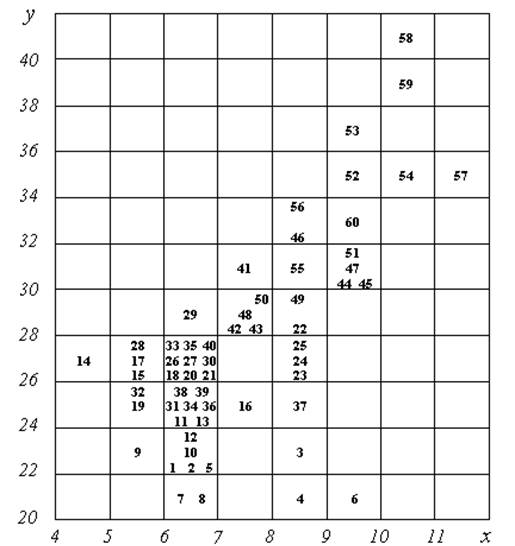
Рис. 1. Кореляційне поле
Підраховуємо на кореляційному полі кількість спостережень (частоти mij), що попадають у ту саму клітинку, і записуємо ці числа у відповідні клітинки табл. 2. Оскільки всі дані в одній клітинці осереднюються на її центр, у графах x і y табл. 2 наводимо лише їхні середні значення по групах. У останньому рядку й в останньому стовпчику кореляційної таблиці обчислюємо суми частот по стовпцях і суми частот по рядках:
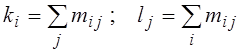 .
.
Перший і останній рядки табл. 2 (рядки x, k) утворюють варіаційний ряд розподілу показника x; перший і останній стовпчики таблиці (стовпці y, l) – варіаційний ряд показника y; уся таблиця характеризує спільний розподіл двох показників x, y. Будь-який стовпець таблиці містить частоти умовного розподілу показника y при фіксованому x; аналогічно, будь-який рядок таблиці містить частоти умовного розподілу показника x при фіксованому y .
Кореляційна таблиця
|
x |
|||||||||
|
y |
4.5 |
5.5 |
6.5 |
7.5 |
8.5 |
9.5 |
10.5 |
11.5 |
l |
|
41 |
1 |
1 |
|||||||
|
39 |
1 |
1 |
|||||||
|
37 |
1 |
1 |
|||||||
|
35 |
1 |
1 |
1 |
3 |
|||||
|
33 |
2 |
1 |
3 |
||||||
|
31 |
1 |
1 |
4 |
6 |
|||||
|
29 |
1 |
4 |
2 |
7 |
|||||
|
27 |
1 |
3 |
9 |
3 |
16 |
||||
|
25 |
2 |
7 |
1 |
1 |
11 |
||||
|
23 |
1 |
5 |
1 |
7 |
|||||
|
21 |
2 |
1 |
1 |
4 |
|||||
|
k |
1 |
6 |
24 |
6 |
11 |
8 |
3 |
1 |
60 |
Тепер ми можемо побудувати графік кореляційної залежності (графік емпіричної лінії регресії). Нагадуємо, що кореляційна залежність – це залежність центрів групування одного показника від значень іншого. Так, для розрахунку вузлів залежності y від x необхідно знайти всі “центри ваги” у вертикальних смугах табл. 2 (вважаючи частоти вагами) :
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.