Пусть X = (X1, ,.., Хn) — выборка объема n из распределения L(x) и x = (x1, ..., xn) — наблюдавшееся значение X. Каждой реализации х выборки X можно поставить в соответствие упорядоченную последовательность [4]
x(1)<=x(2)<=…<=x(n) (1.1)
где x(1)=min(x1, ...,xn), x(2) — второе по величине значение среди x1,…, xnи т. д., x(n) = max(x1,…, xn).
Обозначим через X(k) случайную величину, которая для каждой реализации х выборки X принимает значение x(k), k = 1, ..., n. Так по выборке X определяют новую последовательность случайных величин Х(1), ..., Х(n), называемых порядковыми статистиками выборки [4]; при этом Х(k]—k-я порядковая статистика, а X(1), и X(n) — экстремальные значения выборки. Из определения порядковых статистик следует, что они удовлетворяют неравенствам
X(1)<=X(2)<=…<=X(n) (1.2)
Эту последовательность называют вариационным рядом выборки.
Симметричные относительно концов элементы последовательности Х(m) и Х(n-m+1) иногда называют соответственно m-м наименьшим и m-м наибольшим значениями выборки (m=1, 2, ...); при m= 1 получаем экстремальные значения выборки. Итак, вариационный ряд— это расположенные в порядке возрастания их величин элементы выборки. Отметим, что для заданной реализации x = (x1, ..., xn) выборки X = (X1, ,.., Хn) реализацией последовательности (1.2) является последовательность (1.1).
1.3. Эмпирическая функция распределения
Определим для каждого действительного х случайную величину mn(х), равную числу элементов выборки Х = (Х1 ..., Xn) [5], значения которых не превосходят х, т. е.
mn(х)= |{j:Xj<=x}|
где через |А| обозначено число элементов конечного множества А, и положим Fn(x)= mn(х)/n. Функция Fn(x) называется эмпирической функцией распределения (соответствующей выборке X) [5]. Функцию распределения F{x) наблюдаемой случайной величины x в этом случае называют иногда теоретической функцией распределения.
По своему определению эмпирическая функция распределения — случайная функция: для каждого х Î R значение Fn (х) — случайная величина, реализациями которой являются числа 0, 1/n, 2/n, ..., {n — 1)/n, n/n = 1, и при этом
P (Fn(x) = k/n) = P (mn(х)=k).
Но из определения mn(х) следует, что L (mn(х)) = Bi (n, р), где р = Р (x<=х) = F (х). Поэтому
P (Fn(x) = k/n) = Cnk Fk(x)(1-F(x))n-k, k = 0, 1, ..., n.
Итак, эмпирическая функция распределения (как и вариационный ряд)— некоторая сводная характеристика выборки. Для каждой реализации х выборки X функция Fn(x) однозначно определена и обладает всеми свойствами функции распределения: изменяется от 0 до 1, не убывает к непрерывна справа. При этом она кусочно-постоянна и возрастает только в точках последовательности (1.1). Если все компоненты вектора х различны (в последовательности (1.1) все неравенства строгие), то функция Fn(x) задается [5], очевидно, соотношениями
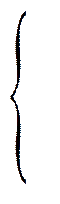
0 при x<x(1),
Fn(x) = k/n при x(k) ≤ x ≤ x(k+1),
1 при x ≥ x(n),
т. е. в этом случае величина всех скачков равна 1 /n. В общем случае эмпирическую функцию распределения можно записать в виде
Fn(x) = 1/n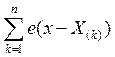 (1.3)
(1.3)
где е(х) — функция единичного скачка [6] (функция Хевисайда):
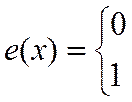 при x<0, при x>=0.
при x<0, при x>=0.
В представлении (1.3) хорошо видна зависимость Fn(x) от выборки X.
Эмпирическая функция распределения играет фундаментальную роль в математической статистике. Важнейшее её свойство состоит в том, что при увеличении числа испытаний над случайной величиной x происходит сближение этой функций с теоретической.
Таким образом, если объем, выборки большой, то значение эмпирической функции распределения в каждой точке х может служить приближенным значением (оценкой) теоретической функции распределения в этой точке. Функцию Fn(x) часто называют в этом случае статистическим аналогом для F (х).
1.4. Проверка гипотез о виде распределения
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.