Первым ГК
набора первичных признаков Х=(х1,х2,…,хn) называется такая линейная комбинация этих признаков,
которая среди прочих линейных комбинаций обладает наибольшей дисперсией.
Геометрически это означает, что первый ГК ориентирован вдоль направления
наибольшей вытянутости гиперэллипсоида рассеивания исследуемой совокупности данных.
Второй ГК имеет наибольшую дисперсию рассеивания среди всех линейных
преобразований, некоррелированных с первым ГК, и представляет собой проекцию на
направление наибольшей вытянутости наблюдений в гиперплоскости,
перпендикулярной первому ГК. Вообще, j–м ГК системы исходных признаков Х=(х1,х2,…,хn) называется такая линейная комбинация этих признаков,
которая некоррелирована с (j-1)
предыдущими ГК и среди всех прочих некоррелированных с предыдущими (j-1) ГК обладает наибольшей дисперсией. Отсюда следует, что
ГК занумерованы в порядке убывания их дисперсий, т.е.  ,
а это дает основу для принятия решения о том, сколько последних ГК можно без
ущерба изъять из рассмотрения.
,
а это дает основу для принятия решения о том, сколько последних ГК можно без
ущерба изъять из рассмотрения.
2 Работа на компьютере
Выполнение данной работы производится с программным пакетом Statistica; версия 6.0.
2.1 Представление многомерных данных
1. Из папки Examples - Datasets открываем файл данных, озаглавленный Activities, в котором приведены различные характеристики образа жизни для 28 групп людей. В качестве активных переменных использовано семь видов социальной активности: work (работа), transport (транспорт), children (дети), household (домашний быт), shopping (покупки), personalcare (личное время), meal (еда). Показателем является общее время, затраченное на данный вид деятельности представителями группы в часах. В качестве вспомогательных признаков выбраны: sleep (сон), TV (телевизор), leisure (досуг). В файл данных введена дополнительная переменная gender (пол), принимающая значения male (мужчины) и female (женщины). Для присвоения меток точкам на графиках добавлен группирующий признак geo. region (регион). Часть таблицы исходных данных приведена на рис.1.

Рисунок 1 - Матрица объект-признак
2. Перейти к матрице признак – признак посредством следующих действий: в командной строке окна выбрать опцию Statistics, в которой указать позицию BasicStatistics / Tables. В открывшемся окне отметить CorrelationMatrices и нажать OK. Далее выбрать первые семь переменных из первого списка. В итоге должна получиться матрица корреляций между признаками размерностью 7х7, вид которой показан на рис.2.
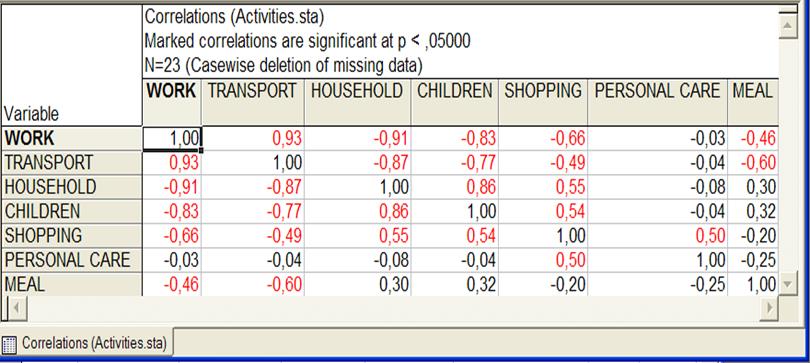
Рисунок 2 - Матрица признак - признак
При обработке данных в этом случае строки с пропущенными данными исключаются из рассмотрения, поэтому из исходных 28 строк остается 23.
3. Перейти к матрице объект-объект следующими операциями: в командной строке окна выбрать опцию Statistics, в которой указать позицию Multivariate Exploratory Techniques и далее - Cluster Analysis - Joining, после чего нажать ОК. В открывшемся окне кластерного анализа, показанном на рис.3, в опции Сlusterвыбрать Cases, поскольку группируются объекты и нажать ОК.
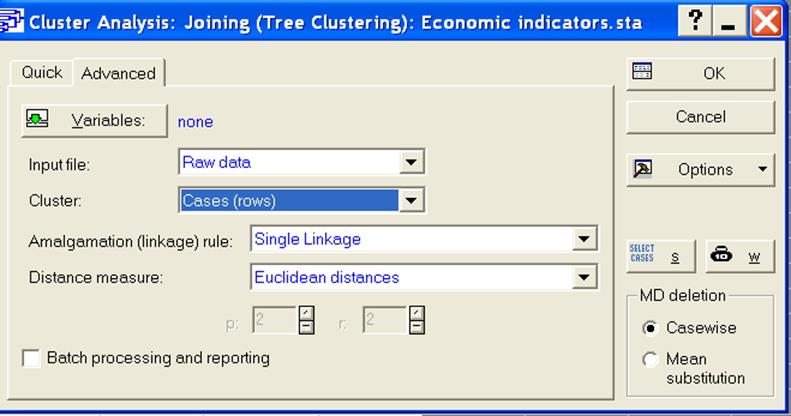
Рисунок 3 - Окно кластерного анализа
В открывшемся окне JoiningResults (Результатов объединения) выбрать DistanceMatrix (Матрицу расстояний), которая и представляет собой матрицу «объект-объект», размерностью 23х23. Часть этой таблицы приведена на рис.4.
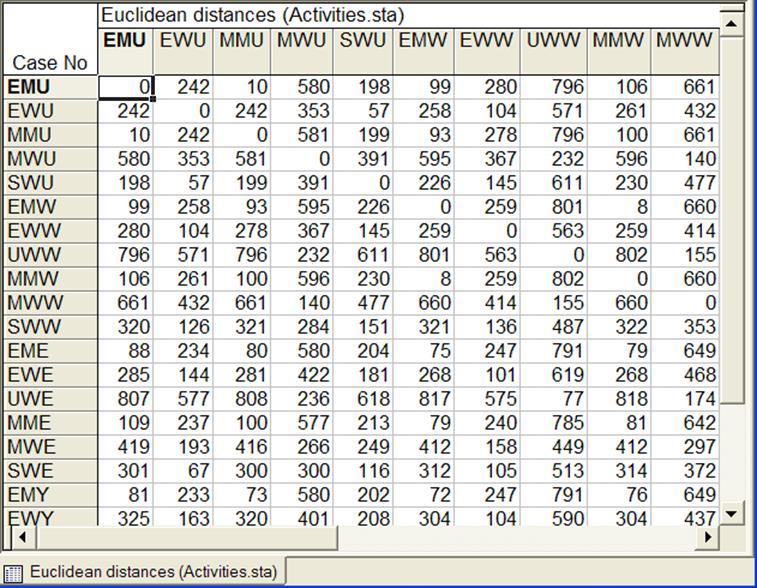
Рисунок 4 - Матрица объект-объект
Пользуясь такой матрицей, можно построить дендрограмму объединения объектов, сходных или различных по семи признакам. Для этого в окне JoiningResultsнажать клавишу Verticalicicleplot, в результате чего приходим к графику, показанному на рис.5.
Полученная дендрограмма указывает порядок и уровень объединения объектов, сходных между собой, а также сформировавшиеся кластеры (группы) сходных объектов. В данном примере образовано 4 кластера.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.