- вычисление ошибки и ее обратное распространение;
- регулирование весов.
После обучения сети ее использование состоит только из вычислений первой фазы. Хотя обучение сети может представлять собой медленный процесс, обученная сеть выполняет свою задачу очень быстро.
Схема алгоритма ОРО показана на рис.4.
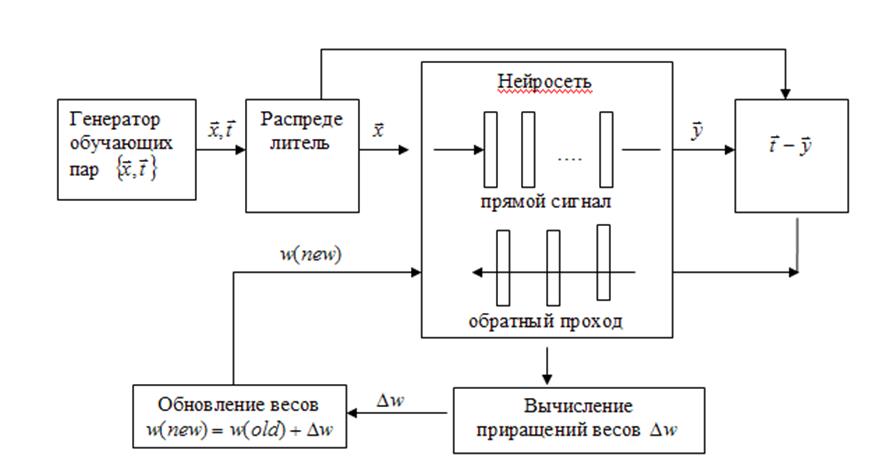
Рисунок 4 - Алгоритм метода ОРО
2 Работа на компьютере
Выполнение данной работы производится с программным пакетом StatisticaNeuralNetworks (SNN). ИНС предназначены, в основном, для решения задач классификации и регрессии. В данной работе обучение методам работы с ИНС проводится на примере задачи классификации. Ошибочная классификация или, иначе говоря, «перепутывание» классов приводит, по существу, к оценке риска как доле неправильно распознанных объектов. Далее обучение работе с пакетом выполняется как последовательность следующих шагов:
1.В состав пакета SNN входит файл данных Iris.sta , относящийся к классической задаче классификации ирисов, предложенной еще в 1936г. известным английским статистиком Р.Фишером. Этот пример во многих программных продуктах считается как своего рода испытательный полигон.
Рассматриваются три сорта цветов ириса: Setosa, Versicolor, Virginica. Всего имеется по 50 экземпляров каждого вида, и каждый из них характеризуется четырьмя величинами: длиной и шириной чашелистика, длиной и шириной лепестка.
Цель работы заключается в том, чтобы обученная ИНС предсказывала тип нового, предъявленного сети цветка по набору измерений из четырех признаков.
Открыть файл Iris.sta через опцию File - Open (Файл – Открыть). На экране появится таблица данных, состоящая из 150 строк и 5 столбцов. В случае, если числа первого столбца указаны серым цветом («не учитываемые»), то при помощи правой клавиши мыши выделить этот столбец и отмаркировать его как Input (Входной). Таким образом, файл содержит 4 входных переменных, подтверждением чему служит цифра «4» в поле «Variables», и одну выходную номинальную переменную, имеющую три значения: Setosa, Versicolor, Virginica, которая определяет тип цветка. На рис.5 показана часть таблицы исходных данных.
Кроме того, разделим выборку данных из 150 цветков на два множества: обучающее, состоящее из 80 цветков (показаны в таблице черным цветом), и контрольное из 70 экземпляров (показаны красным цветом). По первому множеству сеть обучается, второе - используется при контрольных проверках. Эти цифры приведены в окнах в верхней части таблицы. Как видно из таблицы, эти два множества перемешаны случайным образом. При необходимости данные могут еще раз перемешаны путем выбора опции Edit - Cases – Shuffle - All(Редактор – Строки - Перемешать - Все).
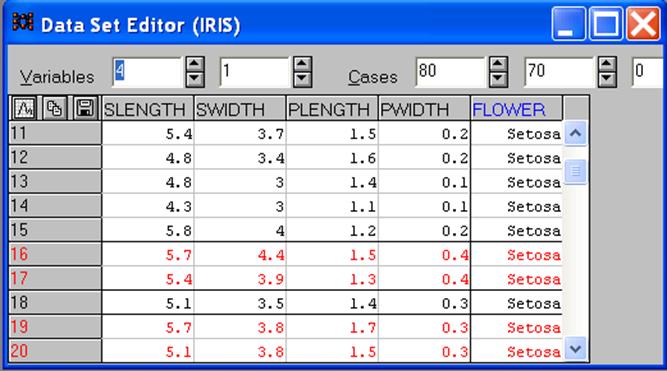
Рисунок 5 - Часть таблицы исходных данных
Тип переменной обозначается цветом, которым высвечивается ее имя в заголовке столбца таблицы:
· Входная - черный;
· Выходная - синий;
· Входная / выходная - зеленый;
· Неучитываемая - серый.
2. Перед конструированием сети уточним цель задачи классификации. В этой задаче необходимо определить, к какому из нескольких заданных классов принадлежит входной набор данных. Примерами могут служить предоставление кредита (относится ли данное лицо к группе высокого или низкого риска), контроль качества продукции (годная, брак), распознавание подписи (подлинная, поддельная). Во всех этих случаях на выходе требуется всего одна номинальная переменная.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.