Декодирующее устройство
содержит два n -разрядных регистра РП-1 и РП-2, устройство
умножения на проверочные полином В(К) (ячейки ![]() с
сумматором по модулю два) для вычисления синдрома и селектор синдромов
допустимых форм ошибок.
с
сумматором по модулю два) для вычисления синдрома и селектор синдромов
допустимых форм ошибок.
В исходном состоянии ключ
Кл1 находится в положении 1, а ключи Кл2 и Кл3 разомкнуты. В ячейки регистра
РП-1 вводится принятая комбинация (n тактов). Затем замыкается ключ
Кл2 ив течение n –
тактов вычисляется синдром ошибки, который вводится в регистр памяти РП-2. При
этом регистр РП-1 образует фильтр-пробку для принятой комбинации. Через 2n
тактов с начала работы декодера в регистре памяти РП-2 образуется комбинация
синдрома ошибки ![]()
После этого Кл1 переводитcя в положение 2, ключ К2 размыкается, а ключ Кл3 замыкается. Символы принятой комбинации черев исправляющий сумматор по модулю два поступает на выход декодера. Одновременно идет сдвиг вправо символов синдрома ошибки, записанных в РП-2. В тот момент, когда искаженный символ принятой комбинации окажется на входе исправляющего сумматора, селектор вырабатывает сигнал единицы и производится коррекция ошибочного символа.
Наиболее сложная часть
декодера - селектор, т.к. он должен выдавать на исправлявший сумматор вектор
ошибки xi(k) . Для исправления ![]() ошибок
необходимо настроить селектор на
ошибок
необходимо настроить селектор на ![]() синдромов. Селектор
значительно упрощается, если использовать метод перевода синдрома s – кратной ошибки к синдрому (s-1)
- кратной ошибки. Такая схема дается
в примере 1.11, где рассматривается нахождение синдрома ошибки.
синдромов. Селектор
значительно упрощается, если использовать метод перевода синдрома s – кратной ошибки к синдрому (s-1)
- кратной ошибки. Такая схема дается
в примере 1.11, где рассматривается нахождение синдрома ошибки.
Пример 1.11. Блок – схема
для кода (7.3) с ![]() приведена на рис. 1.10.
приведена на рис. 1.10.
Работу схемы рассмотрим на
примере кодовой комбинации ![]() . Пусть вектор ошибки
. Пусть вектор ошибки ![]() , тогда принятая кодовая комбинация
, тогда принятая кодовая комбинация ![]() .
.
Принятая кодовая комбинация U(k) вводится в регистр памяти РП – 1, начиная со старшего разряда, значит, первым подлежит исправлению символ старшей позиции. Синдром одиночной ошибки в этом случае равен:
![]() .
.
Все остальные векторы одиночной ошибки дают синдромы,
которые определяются из найденного согласно (1.33). Поэтому для
исправления одиночной ошибки селектор настраивается на комбинацию ![]() .
.
Так как код позволяет
исправлять и пакет из двух ошибок, то найдем синдром, соответствующий вектору
ошибки ![]() :
:
![]() .
.
Для перевода этого синдрома к синдрому одиночной ошибки достаточно вычесть из него синдром ошибки S1 и результат сдвинуть на один разряд вправо.
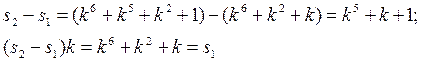
Для выполнения этих операций в регистр РП – 2 встроены сумматоры по модулю два в соответствии с полиномом синдрома одиночной ошибки. При этом синдром пакета из двух ошибок переводится к синдрому одиночной ошибки, синдром одиночной ошибки переводится в нулевой ветер. После окончания цикла исправления ненулевой остаток в РП – 2 может быть использован для обнаружения некорректируемых ошибок.
В таблице 1.6 показан процесс формирования синдрома одиночной ошибки и процесс коррекции, если вектор ошибки
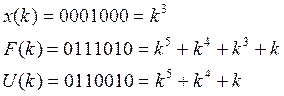
Таблица 1.5
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.