На малий. 2.4 (a) у якості центрального обраний елемент 3. Індекси починають змінюватися з кінців масиву. Індекс i починається ліворуч і використається для вибору елементів, які більше центрального, індекс j починається праворуч і використається для вибору елементів, які менше центрального. Ці елементи міняються місцями – див. мал. 2.4 (b). Процедура QuickSort рекурсивно сортує два подмассива, у результаті виходить масив, представлений на мал. 2.4 (c).
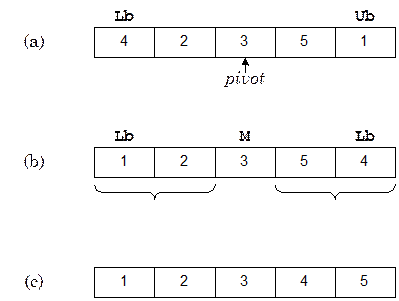
Рис. 0.4: Приклад роботи алгоритму Quicksort
У процесі сортування може знадобитися пересунути центральний елемент. Якщо нам повезе, обраний елемент виявиться медіаною значень масиву, тобто розділить його навпіл. Припустимо на хвилинку, що це й справді так. Оскільки на кожному кроці ми ділимо масив навпіл, а функція Partition зрештою перегляне всі n елементів, час роботи алгоритму є O(n lg n).
В якості центрального функція Partition може попросту брати перший елемент (A[Lb]). Всі інші елементи масиву ми порівнюємо із центральним і пересуваємо або вліво від нього, або вправо. Є, однак, один випадок, що безжалісно руйнує цю прекрасну простоту. Припустимо, що наш масив із самого початку відсортований. Функція Partition завжди буде одержувати в якості центрального мінімальний елемент і тому розділить масив найгіршим способом: у лівому розділі виявиться один елемент, відповідно, у правом залишиться Ub – Lb елементів. Таким чином, кожний рекурсивний виклик процедури quicksort усього лише зменшить довжину сортируемого масиву на 1. У результаті для виконання сортування знадобиться n рекурсивних викликів, що приводить до часу роботи алгоритму порядку O(n2). Один зі способів побороти цю проблему – випадково вибирати центральний елемент. Це зробить найгірший випадок надзвичайно малоймовірним.
Реалізація
Реалізація алгоритму на Си перебуває в розділі 4.3. Оператори typedef T і compGT варто змінити так, щоб вони відповідали даним, збереженим у масиві. У порівнянні з основним алгоритмом є деякі поліпшення::
У розділі 4.4 ви знайдете також qsort – функцію зі стандартної бібліотеки Си, що, у відповідності назвою, заснована на алгоритмі quicksort. Для цієї реалізації рекурсія була замінена на ітерації. У таблиці 2.1 приводиться час і розмір стека, затрачувані до й після описаних поліпшень.
|
Time (ms) |
stacksize |
|||
|
count |
before |
after |
before |
after |
|
16 |
103 |
51 |
540 |
28 |
|
256 |
1,630 |
911 |
912 |
112 |
|
4,096 |
34,183 |
20,016 |
1,908 |
168 |
|
65,536 |
658,003 |
470,737 |
2,436 |
252 |
Таблиця 0.1: Вплив поліпшень на швидкість роботи й розмір стека
У даному розділі мі порівнавним описані алгоритми сортування: вставками, Шелла й швидке сортування. Є трохи факторів, що впливають на вибір алгоритму в кожній конкретній ситуації:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.