Функции планирования конвейерной конструкции DLX с и без обработки прерываний очень похожи. Выполнение начинается в цикле T = 0, который является первым циклом после сброса (table 5.11). Согласно лемме 5.10, первая команда I0 ISR выбирается в цикле T = 0, и
IП(0, 0) = 0.
Команды все еще выбираются в программном порядке и перемещаются в жесткой конфигурации через этапы 0 и 1:
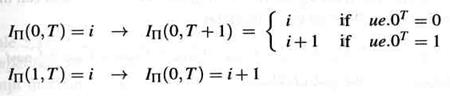
Любая команда продвигается самое большее на один этап за цикл, и она не может быть остановлена, как только синхронизируется с этапом 2. Однако, при активном сигнале JISR команды обрабатываемые на этапах 1 - 3 выселяются из конвейера. Таким образом, IП(k,T) = i /\ (JISRT= 0 V k = 0) подразумевает
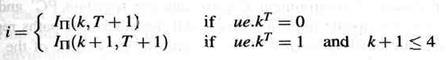
и для k>=2 команды выполняются на полной скорости:
IП(k,T) = i /\ JISRT = 0 -> IП(k+1,T + 1) = i.
Обратите внимание, что при JISR = 1, сигналы разрешения обновления этапов 0 - 4 активны, тогда как на остальных этапах - неактивны.
Стоимость и задержка
Вычисление инвертированного сигнала опасности /dhazтребует сигналов опасности данных двух GPR операндов Aи Bи сигнала опасности данных dhazSоперандов SPR.
/dhaz = (dhazA V dhazB] NOR dhazS.
Так как для обоих операндов GPR обнаружение опасности фактически одинаково, стоимость и задержка сигнала /dhazможет быть смоделирована как
Cdhaz = 2 • CdhazA + CdhazS + Cor + Cnor Adhaz = max{AdhazA + Dor, AdhazS] + Dnor.
Инвертированный флаг /busy, который объединяет два сигнала Dbusyи Ibusy, зависит от флагов окружений памяти. Его стоимость и задержка могут быть смоделированы как
Cbusy = 2 * Cand + 3 * Cnor
Abusy = max{AIMenv(flags), ADMenv(flags)}+Dand + 2*Dnor.
Два сигнала синхронизации CE1 и CE2 зависят от флага занятости, флага опасности данных /dhazи флагов JISR.
JISR = jisr.4 /\ full.4 /JISR = jisr.4 NAND full.4.
Предположим, что сигнал сброса имеет нулевую задержку. Оба синхроимпульса тогда могут быть сгенерированы со следующей стоимостью и задержкой
CCE = 3 • Cor + Cnor + Cand + Cdhaz + Cbusy + Cand + Cnand
aJISR = max{Dand , Dnand}
aCE = rnax{Adhaz , ajisr , Abusy} + Dand + Dor.
Ядро механизма останова - схема с рисунка 5.19. Кроме того, механизм останова генерирует сигналы синхронизации и разрешает обновление регистров и памяти. Только память данных, два файла регистров, выходные регистры окружения CApro, и регистры PC' и DPC имеют непростые сигналы запроса обновления. Все другие регистры путей данных R € out(i) синхронизируются ue.i. Поэтому стоимость и время цикла всего механизма останова может быть смоделирована как
Cstall = 3 • Cff + Cor + 5 • Cand
+ CCE + Cnand + Cnor + Cor + Cinv + 9 * Cand Tstall = ace + 3 • Dand + 8
+ max{DSF (w, ce; 6,32) + Dff , Dram3 (32,32)}
Таблица 5.12 Стоимость путей данных конвейерной конструкции DLX с/без аппаратными прерываниями
|
окружение |
EX |
RF |
PC |
CA |
buffer |
FORW |
DP |
|
DLXn DLXn |
3315 3795 |
4066 7257 |
1906 2610 |
471 |
408 2064 |
812 1624 |
13010 20610 |
|
увеличение |
14% |
78% |
37% |
- |
406% |
100% |
58% |
5.6.4 Стоимость и задержка аппаратуры DLXП
В дальнейшем мы определим стоимость и время цикла конструкции DLXПи сравним эти значения с конвейерной конструкцией DLXπбез обработки прерываний.
Стоимость путей данных
За исключением схемы отправления FORW, схемотехника верхнего уровня путей данных двух конструкций DLX с поддержкой прерываний одинакова. Поэтому стоимость путей данных DPконструкции DLXП (рисунок 5.13) может быть выражена как
cDP = CIMenv + CIRenv + CPCenv + CDaddr
+ CEXenv + CDMenv + CSH4Lenv + CRFenv + Cbuffer + CCAenv + CFORW + 8 • Cff (32).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.