![]() – називають непоясненими
відхиленнями, тобто відхиленнями, які не можна пояснити за допомогою
регресійної прямої.
– називають непоясненими
відхиленнями, тобто відхиленнями, які не можна пояснити за допомогою
регресійної прямої.
Зведемо (7.8) у квадрат і обчислимо суму за всіма значеннями і:
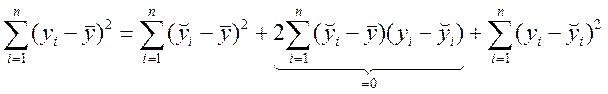 ;
;
Розділимо на n:
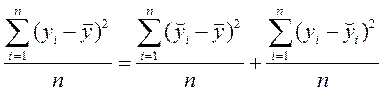 ;
;
![]() .
.
Оскільки модель відображає вплив на результативну ознаку лише частину реальних факторів, регресійний аналіз пояснює тільки частину дисперсії відгуку (загальної дисперсії).
Загальна дисперсія = дисперсія, що пояснюється регресійним аналізом + залишкова дисперсія.
![]() ,
,
![]() ,
,
де s2заг – загальна дисперсія;
s2регр – дисперсія, що пояснюється регресією;
s2зал – дисперсія помилок.
Для оцінки якості моделі вводиться коефіцієнт детермінації, що показує, яка частина варіації пояснюється за допомогою регресійної залежності
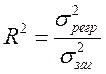 ,
,
або
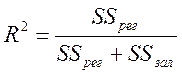 .
.
Оскільки
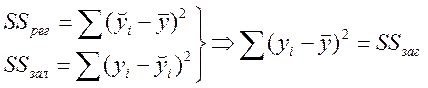 ,
,
тобто
![]() ,
,
то, остаточно,
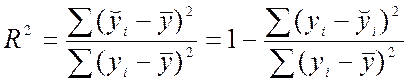 .
.
Коефіцієнт детермінації показує, яка частина варіації результативної ознаки Y враховується в моделі й обумовлена впливом на неї незалежних факторів, врахованих у моделі. Можливі значення коефіцієнта детермінації належать відрізку [0;1]. Чим ближче R2 до 1, тим краща якість моделі. Якість моделі вважається прийнятною, якщо коефіцієнт детермінації не нижче 0,96.
h – індекс
кореляції. Він, як і ![]() R2, відображає точність моделі й може
використовуватися при будь-якій формі зв'язку. При прямолінійному
зв'язку індекс кореляції дорівнює коефіцієнту кореляції.
R2, відображає точність моделі й може
використовуватися при будь-якій формі зв'язку. При прямолінійному
зв'язку індекс кореляції дорівнює коефіцієнту кореляції.
![]()
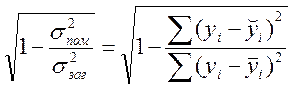 ,
,
![]() .
.
Чим ближче h до 1, тим краще регресійна залежність описує експериментальні дані.
Побудуємо випадкову величину
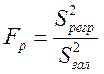 ,
,
де ![]() , k –
кількість параметрів моделі. Для парної лінійної регресії k=2, ( k-1)=1;
, k –
кількість параметрів моделі. Для парної лінійної регресії k=2, ( k-1)=1;
![]() , n
–кількість спостережень.
, n
–кількість спостережень.
Обчислюємо F кр, для заданого рівня значущості α, використовуючи функцію FРАСПОБР пакету Excel:
F кр = FРАСПОБР(a; k-1; n-k).
Якщо![]() , то модель
адекватна.
, то модель
адекватна.
Для перевірки значущості коефіцієнтів регресії застосовуємо t – критерій Стьюдента, за допомогою якого перевіряють, чи значуще ai відрізняється від нуля. Висуваємо гіпотези:
Н0: ![]() ; Н1:
; Н1: ![]() ;
;
Обчислюємо
критеріальне значення 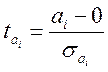 , яке має розподіл
Стьюдента з n-k ступенями вільності,
, яке має розподіл
Стьюдента з n-k ступенями вільності,
де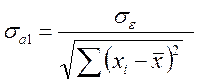 ;
; 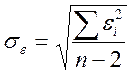 ;
; 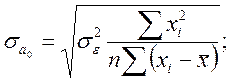
![]() ;
;
n – кількість спостережень; k – кількість параметрів регресії.
Обчислюємо для заданого рівня значущості α критичне значення ![]() .
.
Якщо ![]() , ai –
статистично незначуще, а якщо
, ai –
статистично незначуще, а якщо ![]() , ai
- статистично значуще.
, ai
- статистично значуще.
Якщо виникає ситуація, що ai статистично незначуще відрізняється від нуля, то це означає, що вплив i-го фактору на досліджувану змінну нестабільний.
В Excel для знаходження кращої залежності необхідно побудувати лінію тренда.
1 Будується графік.
2 На графіку виводимо контекстне меню – Додати лінію тренда.
3 Обираємо тип лінії тренда (лінійна, логарифмічна, експонентна, степенева).
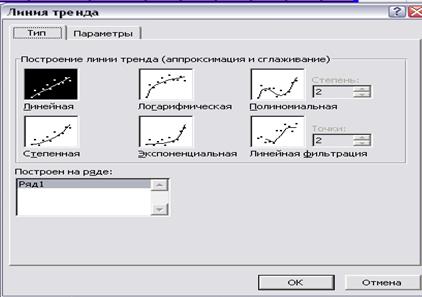
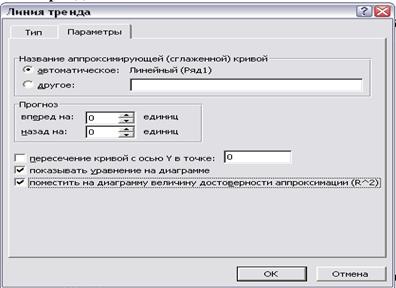
4 У закладці Параметры обираємо:
- показывать уравнение на диаграмме;
- поместить на диаграмму величину достоверности аппроксимации (R^2).
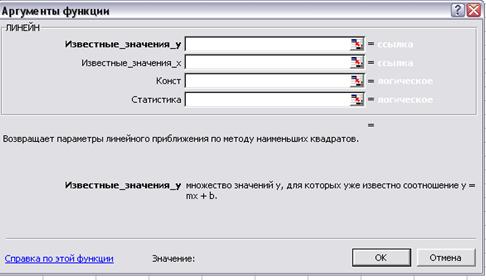
В Excel для побудови лінійної регресії використовується
функція линейн,
що дає рівняння лінійної регресії (![]() =a1х+a0)
і статистику. Цю функцію можна також використовувати для множинної регресії
=a1х+a0)
і статистику. Цю функцію можна також використовувати для множинної регресії ![]() = amхm+…+ a2х2+ a1х+a0 (m змінних впливають
на досліджуваний фактор).
= amхm+…+ a2х2+ a1х+a0 (m змінних впливають
на досліджуваний фактор).
![]() = amхm+…+ a2х2+ a1х+a0 в графі Конст
ставимо 1 (истина),
= amхm+…+ a2х2+ a1х+a0 в графі Конст
ставимо 1 (истина),
якщо
![]() = amхm+…+ a2х2+ a1х в графі Конст
ставимо 0 (ложь).
= amхm+…+ a2х2+ a1х в графі Конст
ставимо 0 (ложь).
· Статистика — логічне значення, що вказує, чи потрібно повернути додаткову статистику для регресії. Якщо аргумент статистика має значення ИСТИНА, то функція ЛИНЕЙН повертає додаткову регресійну статистику.
Натиснути CTRL+Shift+Enter для введення значень масиву.
Отримаємо таблицю результатів:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.