В данном примере оптимальная схема выявлена в результате пассивного поиска, так как число возможных схем невелико. Для случаев, когда узлов графов много оптимальная траектория может отыскиваться как кратчайший (в смысле приведенных затрат) путь на графе при помощи методов динамического программирования.
Изложенный подход, предлагающий фиксированные сроки увеличения пропускной способности дороги, развит в работах кафедры «Изыскания и проектирование железных дорог» МИИТА. В данном случае этот подход применен с учетом особенностей, присущих автомобильным дорогам.
Получено 1.08.2003 г.
ISBN 985-6550-46-7 Проблемы развития транспортных коммуникаций.
Гомель, 2005
УДК 656.21.001.2:681.51
А.К. Головнич
Белорусский государственный университет транспорта
ПРИМЕНЕНИЕ ЛИНГВИСТИЧЕСКИХ МЕТОДОВ
ОБРАБОТКИ ТЕХНИЧЕСКОГО ЗАДАНИЯ НА ПРОЕКТИРОВАНИЕ
В САПР ЖЕЛЕЗНОДОРОЖНЫХ СТАНЦИЙ
Рассматривается возможность программного расчёта путевого развития станции на основе заданных объемов работы обычным текстом. Произвольно сформированное задание на проектирование проходит программно-лингвистический анализ с целью определения значащей информации. Представлены общие алгоритмические подходы распознавания содержательной информации в текстах технических заданий на проектирование транспортных объектов.
Интерактивное взаимодействие проектировщика и программы в процессе разработки проектного решения автоматизированными методами связано с созданием определенной комфортной среды для пользователя. Подготовка исходных данных с заполнением жестко структурированных таблиц часто ограничивает информативность задания на проектирование. Особенности климатического, топографического, экономического, экологического характера, места размещения станции на линии, мощности корреспонденций грузопотоков требуют ввода дополнительных данных, которые не могут быть отражены на фиксированных табличных формах. Выдача всех исходных таблиц приведет к информационной перегруженности программного окна. В этом случае пользователю потребуется дополнительное время для поиска необходимых ячеек и изучения правил их заполнения. Поэтому целесообразно всю табличную структуру исходных данных перенести в область программного кода, а проектировщику предоставить возможность записи задания на проектирование обычным, понятным для него текстом.
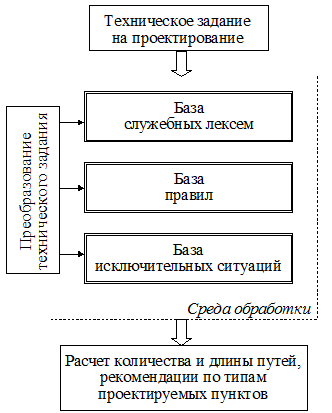
Программа расчета параметров проектируемых пунктов представляет собой три взаимосвязанных алгоритмических модуля обработки исходного задания на проектирование. Основой каждого модуля является соответствующая база данных или знаний (рисунок 1).
В базе служебных лексем хранится неизменяемая, семантически однозначная часть слова. Элементы данного множества содержат ключевые слова, определяющие количественные параметры поездо- и вагонопотока. Для адекватного формализованного представления технического задания, как показывают проведенные автором исследования, достаточно около 20 значимых лексем («грузовые», «транзитные», «переработка», «сборные», «местные», «пассажирские», «дальние», «пригородные», «вагон» и некоторые другие).
База правил определяет набор условий преобразования языковых единиц текста в фиксированные параметры исходных данных. Правила анализа текстовой информации работают по принципу поиска служебных слов, формирования пары связанных лексем (<число> + <служебное слово>) и записи значения полученного параметра в базу.
путевого развития по техническому зданию на проектирование
Данная схема позволяет расширить множество служебных слов, которые компьютерная программа обрабатывает по указанным правилам. Единственным условием дополнения базы информационно-значимых лексем является непременная привязка их к количественному значению. Унарные лексемы требуют использования более изощренных интеллектуальных процедур анализа семантической информации.
База исключительных ситуаций подключается на заключительной стадии подготовки исходных данных для проведения расчета. Данная база теоретически должна представлять полную группу возможных конфликтных событий, приводящих к различным ошибкам в интерпретации исходного текстового материала или полученных результатов. Однако гарантированных методов определения полноты группы «риска» неправильной трансформации текста в настоящее время не существует. Поэтому лишь с определенной вероятностью можно ожидать корректную работу программных комплексов, обеспечивающих автоматизированные расчеты на основе исходных текстов.
Распознавание и выбор служебной информации из технического задания производится по следующей схеме:
если «слово» ![]() {«числа»},
{«числа»},
то записать «слово» в переменную «число».
если «слово» ![]() {«числа»}
{«числа»}
![]() «слово»
>[ Ωmin ]
«слово»
>[ Ωmin ] ![]() «слово»
«слово» ![]() {«база лексем»},
{«база лексем»},
то {«слово» = «служебное»}сопоставить с Nслово
![]() Nслово
= «число».
Nслово
= «число».
Ωmin определяет минимальную мощность лексемы, определяющей смысловое содержание служебного слова. Проведенные исследования показали, что для базы служебных слов САПР железнодорожных станций количество букв в слове, позволяющее однозначно идентифицировать содержание лексемы, Ωmin=5.
Таким образом, все ключевые лексемы, образующие информационную среду последующих расчетов параметров путевого развития, разделяются на три группы: <число>, <объект>, <категория>. Группа <число> определяет количественную характеристику некоторого параметра, группа <объект> состоит из двух элементов («поезд», «вагон»), <категория> содержит элементы, идентифицирующие категорию поездопотока.
Формирование базы исходных данных In для дальнейших расчетов происходит по всем n лексемам текста технического задания на проектирование в соответствии со следующим алгоритмом:
In, (i = 1), ↓ Ti![]() {D}
{D}![]() Ti
Ti![]() {D}
{D}![]() Ki
= D
Ki
= D![]() Ti
Ti![]() {Si}
{Si}![]() Wi = D,(i
= i + 1)↑.
Wi = D,(i
= i + 1)↑.
Операторная запись процесса чтения исходного текста и перевод значимой
информации в базу данных указывает на цикличность производимых операций {n,(i=1)…,(i=i+1)}. Причем данный
шаблон оставляет след в базе данных только в том случае, если Ti![]() {D}
{D}![]() Ti
Ti![]() {D}
{D}![]() Ti
Ti![]() {Si}, в противном случае происходит переход к следующей
лексеме, если не достигнут признак конца текста.
{Si}, в противном случае происходит переход к следующей
лексеме, если не достигнут признак конца текста.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.