Определив интервал (t1–a/2, n–1, ta/2, n–1), который с доверительной вероятностью накрывает значение t, можно найти доверительный интервал для МО M[x] следующим преобразованием:
![]() Þ
Þ
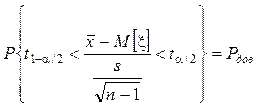 Þ
Þ
Þ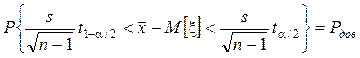 Þ
Þ 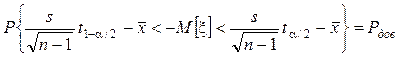 .
.
Учитывая, что ta/2=–t1-a/2
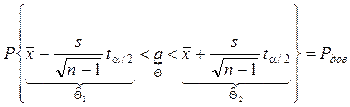 .
.
Следовательно доверительный интервал для МО СВ, имеющей
нормальное распределение с неизвестным СКО найден. Абсолютная погрешность
оценки МО равна 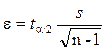 .
.
Построение доверительного интервала для СКО СВ, имеющей нормальное распределение
Пусть известно, что исследуемая СВ x имеет нормальное распределение x~N(M[x],s[x]), а параметры распределения M[x] и s[x] неизвестны. Предположим, что по выборке объема n найдены их точечные оценки:
![]() ,
, 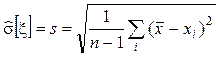 .
.
Для построения доверительного интервала для СКО СВ,
имеющей нормальное распределение, используется вспомогательная СВ (выборочная
статистика) 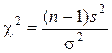 , которая имеет распределение c2
с n=n-1
степенями свободы.
, которая имеет распределение c2
с n=n-1
степенями свободы.
Таким образом, если x~N(M[x],s[x]), то c2 ~c2 (n–1).
Для заданной доверительной вероятности Pдов=1–a, найдём интервал (c2 1–a/2, n–1, c2 a/2, n–1) из условий:
|
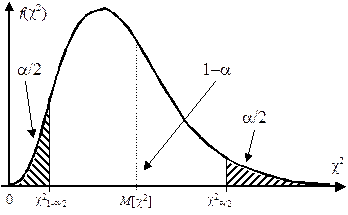
Квантили распределения c2 уровня (1-a/2) и (a/2) для различного числа степеней свободы (n–1) можно найти в специальных таблицах.
Определив интервал (c21–a/2, n–1, c2a/2, n–1), который с доверительной вероятностью накрывает значение c2 , можно найти доверительный интервал для СКО s[x] следующим преобразованием:
![]() Þ
Þ
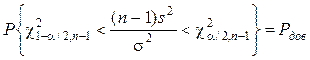 Þ
Þ
Þ
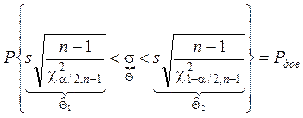 .
.
Следовательно доверительный интервал для СКО СВ, имеющей нормальное распределение, найден.
Послесловие
На сегодняшней лекции мы рассмотрели методы статистической оценки параметров распределения и числовых характеристик СВ.
На следующей лекции мы перейдем к следующему важному разделу математической статистики, связанному с проверкой статистических гипотез, которому посвятим три лекции.
Оценки числовых характеристик случайных величин
Задача оценивания неизвестного параметра ![]() распределения случайной величины x
состоит в подборе приближенной функции V от элементов выборки {x1,
x2,…xn}:
распределения случайной величины x
состоит в подборе приближенной функции V от элементов выборки {x1,
x2,…xn}: ![]() »V(x1, x2,…xn),
которую называют выборочной функцией (статистикой), а её значение:
»V(x1, x2,…xn),
которую называют выборочной функцией (статистикой), а её значение: ![]() =V(x1, x2,…xn)
– оценкой параметра
=V(x1, x2,…xn)
– оценкой параметра ![]() .
.
Точечная оценка ![]() параметра
распределения
параметра
распределения ![]() (числовой характеристики)
случайной величины x определяется одним числом
(числовой характеристики)
случайной величины x определяется одним числом ![]() =V(x1, x2,…xn).
=V(x1, x2,…xn).
Точечная оценка параметра ![]() =V(x1,
x2,…xn) называется состоятельной,
если
=V(x1,
x2,…xn) называется состоятельной,
если 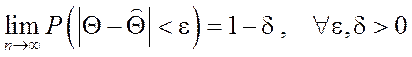 , где e и d –
произвольные сколь угодно малые положительные числа.
, где e и d –
произвольные сколь угодно малые положительные числа.
Точечная оценка параметра ![]() является
несмещенной, если
является
несмещенной, если ![]() .
.
Точечная оценка параметра ![]() называется
асимптотически несмещенной, если
называется
асимптотически несмещенной, если 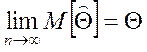 .
.
Точечная
несмещенная оценка
параметра ![]() =V(x1, x2,…xn)
называется эффективной, если она обладает минимальной дисперсией среди других
возможных оценок исследуемого параметра.
=V(x1, x2,…xn)
называется эффективной, если она обладает минимальной дисперсией среди других
возможных оценок исследуемого параметра.
Пусть {x1, x2,…xn} – выборка значений СВ x. Значения элементов выборки можно рассматривать как n случайных величин, каждая их которых имеет распределение Fx(x) с математическим ожиданием M[x].
Вычислим
математическое ожидание оценки ![]() :
:
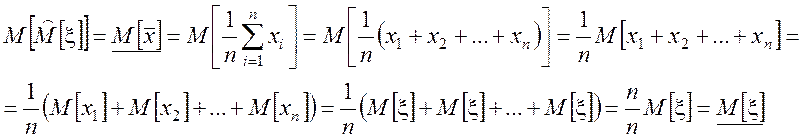 .
.
Доказательство
свойства состоятельности оценки МО как среднего арифметического следует
непосредственно из теоремы Чебышева: при достаточно большом числе независимых
опытов среднее арифметическое наблюдаемых значений случайной величины x
сходится по вероятности к её математическому ожиданию, т.е. 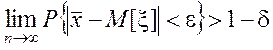 , где
, где  –
среднее арифметическое наблюдаемых значений СВ x, а e
и d – произвольные сколь угодно малые положительные
числа.
–
среднее арифметическое наблюдаемых значений СВ x, а e
и d – произвольные сколь угодно малые положительные
числа.
Интервальная
оценка
характеризует оцениваемый параметр ![]() случайной величины x
двумя числами
случайной величины x
двумя числами ![]() 1 и
1 и ![]() 2 – концами интервала (
2 – концами интервала (![]() 1 ,
1 , ![]() 2),
который накрывает значение оцениваемого параметра
2),
который накрывает значение оцениваемого параметра ![]() с
заданной вероятностью.
с
заданной вероятностью.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.
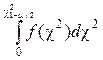 =a/2;
=a/2; 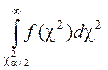 =a/2.
=a/2.