Примечание:
1. Значения имеющие знак инверсии имеют активный низкий уровень (L), без инверсии, соответственно, наоборот.
2. Уже при разработке примера реализации 2-х машинных
команд, была замечена даже не ошибка, а нерациональное использование 1 бита МК.
Этот бит разрешение вывода данных на DB с ОП (![]() ).
Вместо него можно было использовать бит разрешения работы с памятью (
).
Вместо него можно было использовать бит разрешения работы с памятью (![]() ),
т.к. память не может быть использована с отключённым входным/выходным буфером
данных. В принципе, с этим битом или без него, система должна работать
(теоретически).
),
т.к. память не может быть использована с отключённым входным/выходным буфером
данных. В принципе, с этим битом или без него, система должна работать
(теоретически).
10. Разработка алгоритмов выполнения 2-х машинных команд [4,5]
Для выполнения команды ЭВМ должна выполнить следующие шаги:
- сформировать адрес команды (увеличение счетчика команд на 2)
- выбрать команду из памяти (по адресу указанному в счетчике)
- декодировать команду (поступление в ПНА КОП и получение начального адреса микропрограммы, выполняющую заданную команду).
- выбрать из памяти величину смещения
- сформировать адрес операнда (смещение+указанное значение во 2 операнде)
- выбрать операнд (выбирается операнд по сформированному адресу)
- выполнить команду (выполнение операции, заданная командой + необходимо разрешить работу ПНА).
Каждая команда состоит из микрокоманд, последовательно выполняющих основные шаги.
В зависимости от типа команды некоторые шаги могут быть опущены [5].
Первые три шага являются общими для всех команд, поэтому не стоит выделять память под эти инструкции для каждой команды. Так же необходимо зарезервировать 1 ячейку РОН под счётчик команд (СК). В данной работе эта ячейка помечена как RG0.
ADDR1, R2
(сложение содержимого регистров R1 и R2 с записью результата в R2)
Данная команда относится к типу команд RR (рис.3). При выполнении таких команд содержимое СК, увеличенное на 2, загружается в RGA и выдаётся сигнал запроса шины по адресу СК+2. Содержимое СК увеличивается на 4. Регистр Din и RGK загружается содержимым ОП по адресу СК, увеличенным на 2. Выполняется команда, находящаяся в СК. На входы ПНА поступает содержимое СК +2 [5].
Блок схема для данной команды приведена на рис. 32.
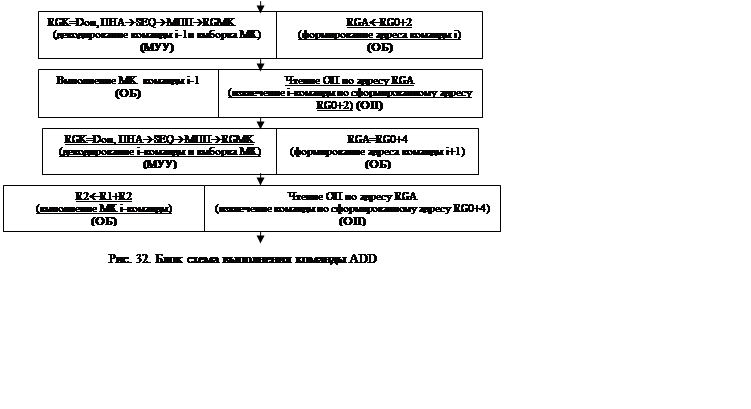
Примечание:
1. Команды i-1 и i+1 типа RR, для их выполнения требуется 1 МК.
2. Подчёркиванием выделены блоки относящиеся к выполнению заданной команды.
Данная блок схема наглядно демонстрирует принцип конвейеризации.
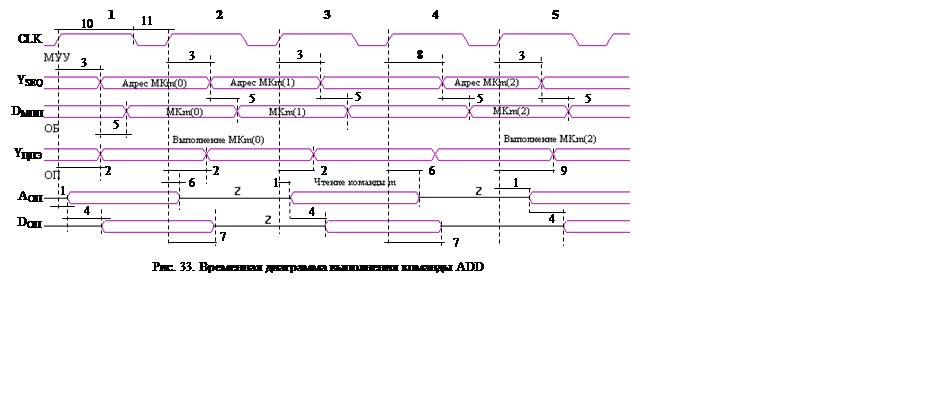
Ниже приведена временная диаграмма работы
устройств при реализации данной команды (рис. 33).
Примечание:
m- текущая команда
Пояснения, на временной диаграмме, относятся только к выполнению команды ADD.
1. Вырабатывается МКm0 на выполнение RG0+2 и пересылку в RGA адреса. МУУ
Получение команды m-1 из ОП по адресу RG0. ОП
Выполнение команды m-2. ОБ
2. Вырабатывается МКm1 и MK(m-1)(n-1) (естественно, это одна МК просто она условно разделена) на дешифрацию команды m-1 и инструкции на работу с ОП команды m. МУУ
Выполняется МКm0: получение адреса RG0+2. ОБ
3. Вырабатывается МК(m+1)0 на выполнение RG0+4 и пересылку в RGA адреса. МУУ
Выполнение команды m-1. ОБ
Получение команды m из ОП по адресу RG0+2. ОП
4. Вырабатывается МКm2 и MK(m+1)(1) на дешифрацию команды m и инструкции на работу с ОП команды m+1. МУУ
Выполняется МК(m+1)0: получение адреса RG0+4. ОБ
5. Вырабатывается МК(m+2)0 на выполнение RG0+6 и пересылку в RGA адреса. МУУ.
Получение команды m+1 из ОП по адресу RG0+4. ОП
Выполнение команды m. ОБ
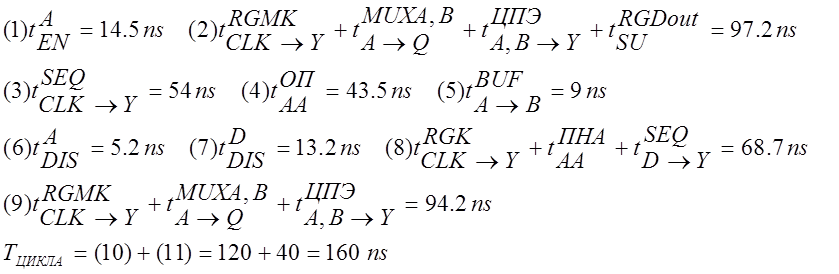 |
LD R1, [R2]
(помещение данных из памяти по адресу находящемся в R2 в R1)
Данная команда относится к типу команд типа RS (рис. 4). Блок схема представлена на рис. 34.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.