Чем длиннее конвейер, тем меньшая часть работы выполняется за тактовый цикл и тем короче можно сделать тактовый цикл. То есть при более длинном конвейере можно при прочих равных условиях достичь более высоких тактовых частот. При этом можно было бы достичь и соответствующего роста производительности, если бы конвейер работал непрерывно, не останавливаясь. Однако на практике параллельная обработка инструкций возможна не всегда, следствием чего являются остановы конвейера. Основные причины остановов — нарушение последовательности выполнения операций при условных переходах и зависимость данных (когда для выполнения инструкции требуется результат другой инструкции, которая еще не завершена). После останова конвейер очищается и снова начинает заполняться, то есть недовыполненные инструкции начинают выполняться сначала. Потеря производительности при этом тем больше, чем конвейер длиннее. Более того, чем длиннее конвейер, тем выше вероятность останова. Поэтому обычно ищется некая компромиссная длина конвейера, при которой выигрыш от распараллеливания все еще превосходит издержки от остановов. В большинстве современных процессоров (серии Intel P6, AMD K7) конвейер имеет 10-12 стадий, а в процессоре Intel Pentium 4 число стадий увеличено до 20.
Для того чтобы снизить потери от остановов из-за нарушения порядка операций при условных переходах, применяется предсказание переходов (Branch Prediction), основанное на анализе уже осуществленных переходов. Поскольку условные переходы встречаются очень часто (по статистике — каждая пятая инструкция), повышение точности предсказаний очень существенно для повышения производительности. Способствует росту производительности и спекулятивное исполнение (Speculative Execution), когда инструкции, следующие за предполагаемым переходом, начинают обрабатываться еще до самого перехода. Проблемы с зависимостью данных во многих случаях могут быть решены путем изменения порядка исполнения инструкций (Out of Order Execution).
По статистике, примерно каждая третья операция в программе — это операция с памятью. Динамическая память, используемая в качестве основной памяти компьютеров, функционирует по сравнению с современными процессорами очень медленно. Поэтому для ускорения операций с памятью используется специальный буфер (кэш-память, или кэш) на основе максимально быстрой памяти. Работа кэш-памяти базируется на эксплуатации присущей программному обеспечению локальности ссылок, которая заключается в преимущественном использовании одних и тех же данных внутри короткого промежутка времени (временная локальность) или данных, располагающихся близко по адресам (пространственная локальность). Для этого в кэш-память заносятся как данные, к которым происходило обращение, так и их окружение — данные из соседних ячеек (блока), которые в совокупности образуют строки кэш-памяти (запоминаются также соответствующие адреса).
Основное требование к кэш-памяти — максимальная производительность, которая определяется как ее быстродействием, так и процентом промахов (Miss Ratio) при обращениях. При увеличении размера кэш-памяти увеличивается и время доступа к данным. То есть можно сделать небольшую быструю кэш-память или большую, но медленную. Или организовать иерархию из двух — 1-го (L1) и 2-го (L2) уровней (см. рис. 2), что является оптимальным решением. В этом случае и объем большой, и время доступа достаточно мало. Важнейшими характеристиками, влияющими на частоту промахов, являются объем, длина строки и ассоциативность кэш-памяти. С ростом объема и длины строки кэш-памяти растет выигрыш соответственно от временной и пространственной локальности. При увеличении ассоциативности (количества строк, на которые может отображаться данный блок) снижается
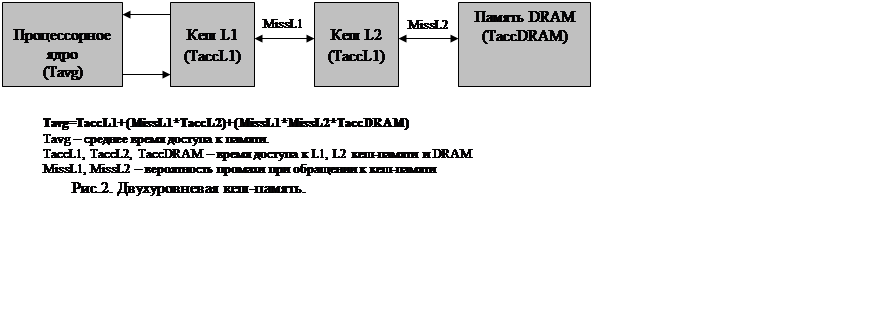 |
вероятность конфликтных ситуаций, когда для отображения данного блока используется строка, занятая другим блоком.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.