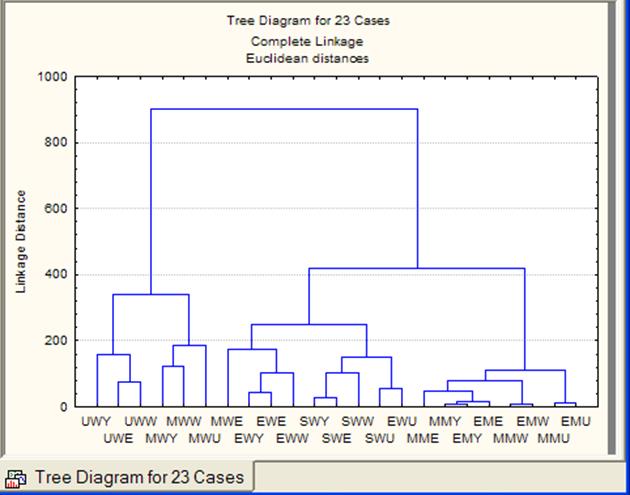
Рисунок 5 - Дендрограмма объектов
2.2 Визуализация многомерных данных
1. Из папки Examples - Datasets открываем тот же самый файл данных Activities.
2. В командной строке окна выбрать опцию Statistics, в которой указать позицию Multivariate Exploratory Techniques и далее - Principal Components & Classification Analysis (Главные компоненты и классификационный анализ). В стартовой панели модуля на вкладке Advanced (расширенная) нажать кнопку Variables (переменные). В открывшемся окне Selectthevariables … в поле Variablesforanalysis(переменные для анализа) выделить первые 7 переменных; в поле Supplementaryvariables (вспомогательные переменные) - переменные sleep - leisure; в поле Activecases variables (переменные с основными наблюдениями) - gender; в поле Grouping variable(группирующая переменная) - geo. region. После этих процедур окно Select the variables … принимает вид, показанный на рис. 6.
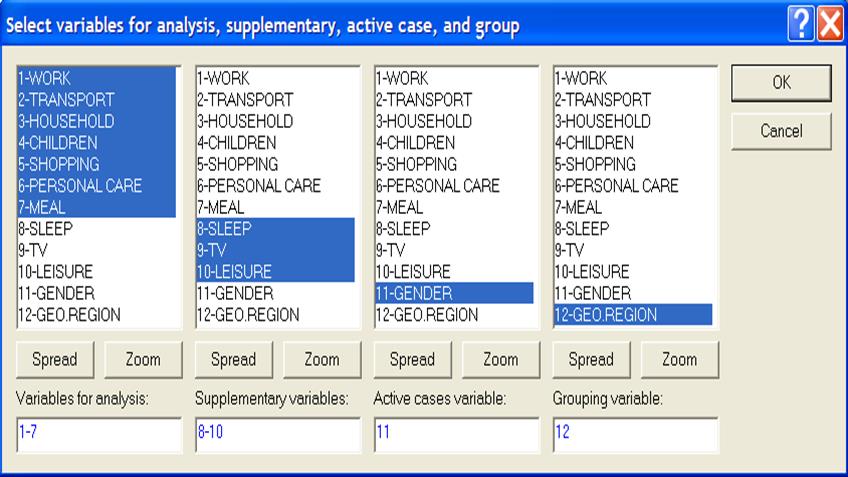
Рисунок 6 - Окно выбора переменных
После нажатия ОК стартовая панель PrincipalComponents & ClassificationAnalysis имеет вид, показанный на рис.7.
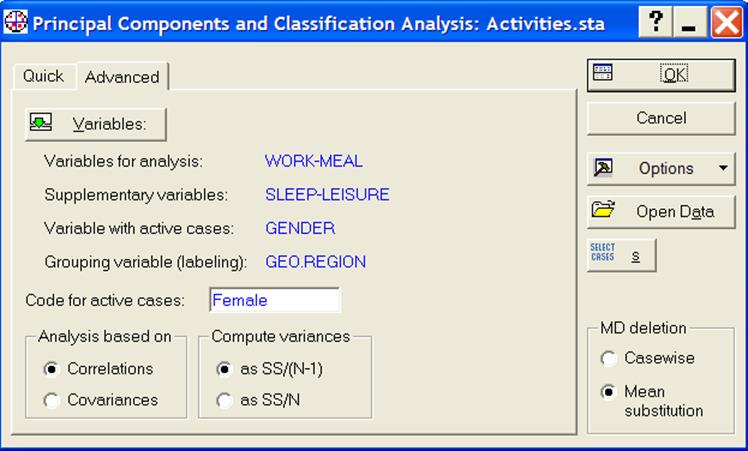
Рисунок 7 - Стартовая панель после выбора переменных
Кроме того, на стартовой панели в поле Codeforactivecases указать значение переменной female в качестве кода для основных наблюдений. Здесь же в рамке Analysisbasedon (анализ основан на …) выбрать опцию Correlations, так как средние значения и дисперсии каждой переменной могут значительно различаться между собой. В рамке MDdeletion (удаление пропущенных данных) указать опцию Meansubstitution (замена средним), а в рамке Computevariances (вычисление дисперсий) - опцию SS/ N-1, поскольку данных не очень много, и выбор другой опции может привести к смещенным оценкам дисперсии. После выбора этих опций нажать ОК.
3. В появившемся окне результатов анализа PrincipalComponents & ClassificationAnalysis в информационной части указано количество основных и вспомогательных переменных и наблюдений (рис. 8).
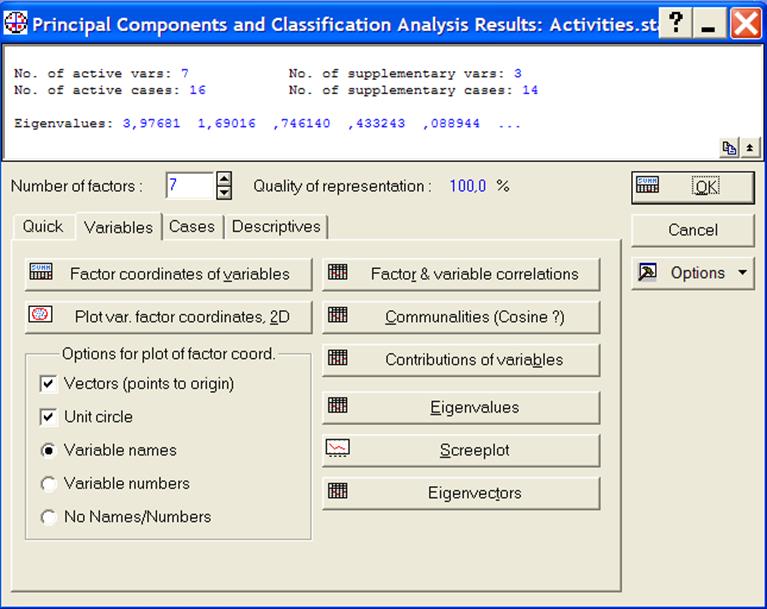
Рисунок 8 - Окно результатов анализа
После нажатия кнопки Screeplot программа построит график изменения собственных чисел (СЧ) корреляционной матрицы, показанный на рис.9.
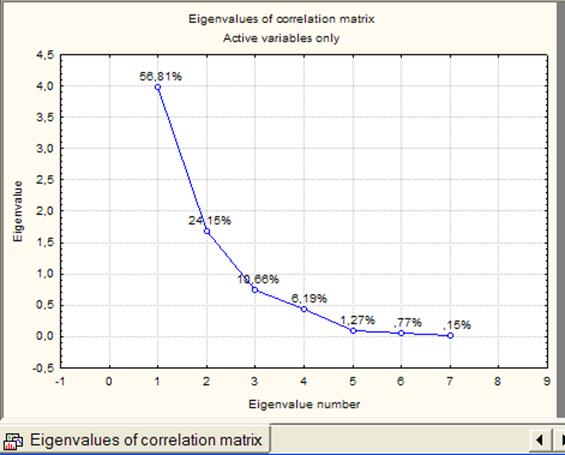
Рисунок 9 - График изменения собственных чисел
Сами СЧ можно увидеть после нажатия кнопки Eigenvalues (собственные числа) в появившейся таблице (рис.10).

Рисунок 10 - Собственные числа
Анализ графика и таблицы позволяет выбрать число выделяемых главных компонентов (ГК). Например, по графику (иногда называемому «каменистой осыпью») можно определить СЧ, начиная с которого график теряет свою кривизну, и убывание СЧ максимально замедляется. Из графика видно, что такими СЧ являются 2 или 3, поэтому число выделяемых ГК может быть равно 2 или 3. Выбрав число, равное 2, введем его в поле Numberoffactors(рис.8), после чего качество представления (Qualityofrepresentation) изменит свое значение со 100% на 81% (рис.11).
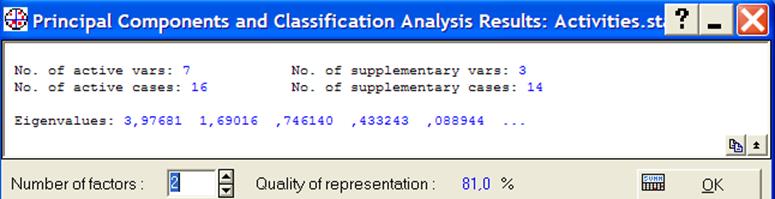
Рисунок 11 - Качество представления при двух факторах
Тот же самый вывод следует из таблицы рис.10, где в последнем столбце приведены значения накопленной суммы СЧ: видно, что при двух оставляемых в анализе СЧ эта сумма составляет примерно 81%. Следовательно, потеря информативности при переходе от 7 СЧ к 2 СЧ составляет около 19%, но зато появляется возможность визуализации многомерных исходных данных.
4. Нажать кнопку Factorcoordinatesofvariables (факторные координаты переменных) для получения таблицы координат исходных переменных в пространстве новых выделенных факторов (ГК) (рис.12).
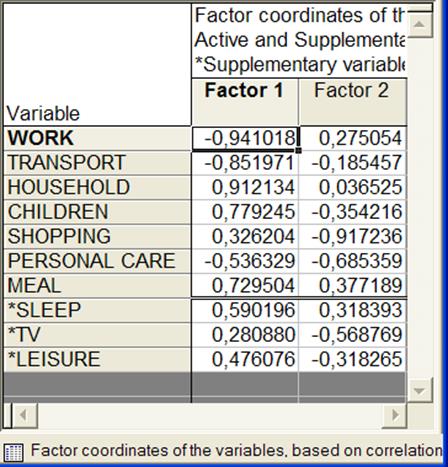
Рисунок 12 - Координаты исходных переменных в пространстве главных компонентов (факторов)
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.