Начальным выборочным моментом k-го порядка ![]() называется
среднее арифметическое k-х степеней вариант выборки, т.е.
называется
среднее арифметическое k-х степеней вариант выборки, т.е.
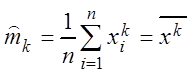
Центральным выборочным моментом k-го порядка ![]() называется среднее арифметическое k-х
степеней отклонения вариант выборки от выборочного среднего, т.е.
называется среднее арифметическое k-х
степеней отклонения вариант выборки от выборочного среднего, т.е.
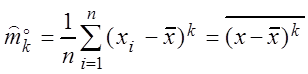 .
.
Эти выборочные моменты являются точечными оценками соответствующих теоретических моментов случайной величины m.
Если Fm(x) = F(x; q1, q2, ... , qr) зависит от r параметров, то естественно потребовать, чтобы моменты k-го порядка случайной величины mсовпадали с выборочными моментами этого же порядка, т.е.
mk = ![]() , k =
, k = ![]() или
или
![]() =
= ![]() k
=
k
= ![]() .
.
В частности, если m – непрерывная случайная величина и fm(x) = f(x; q) , то
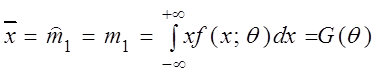 ,
,
отсюда формально находим ![]() .
.
Пример 3.5. По данным случайной выборки найти точечную оценку для параметра l показательного распределения.
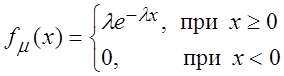 .
.
Решение.q = l,
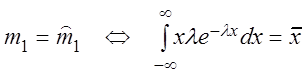 ,
,
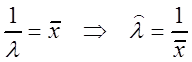 .
.
Пример 3.6. Найти точечные оценки для границ a и bравномерного распределения на отрезке [a, b].
Решение. Записываем равенства теоретических и выборочных начальных моментов двух первых порядков
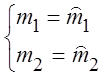 .
.
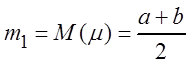 ,
,
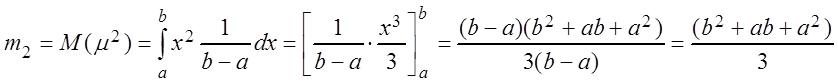 ,
,
![]()
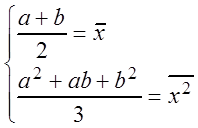 , b = 2
, b = 2![]() – a, a2 + 2a
– a, a2 + 2a![]() – a2 + (2
– a2 + (2![]() – a)2 = 3
– a)2 = 3![]() ,
,
a2 + 2a![]() – a2 + 4
– a2 + 4![]() – 4
– 4![]() a + a2 = 3
a + a2 = 3![]() , a2 – 2a
, a2 – 2a![]() + 4
+ 4![]() – 3
– 3![]() = 0,
= 0,
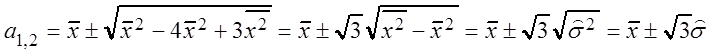 ,
,
b1,2
= 2![]() –
(
–
(![]() ) =
) = ![]() ,
,
так как по определению плотности равномерного распределения a < b, получаем
![]() ;
; ![]() =
= ![]() .
.
3.3.2. Метод наибольшего правдоподобия
Пусть ![]() –
дискретная случайная величина, заданная законом распределения:
–
дискретная случайная величина, заданная законом распределения:
|
|
t1 |
t2 |
. . . |
|
, |
|
Р |
p1 |
p2 |
. . . |
|
Рассмотрим функцию вида L = L(x1, x2, . . . xn; q) = P(x1; q)P(x2; q)×...×P(xn; q), которая называется функцией правдоподобия. Здесь P(xi; q) = P(m = xi).
Функция правдоподобия представляет собой вероятность получения (реализации) выборки. А так как выборка уже имеется, т.е. реализована, то значение этой функции должно быть равно 1. Но в силу случайного характера, как правило, эта функция отлична от 1, но должна быть, по крайней мере, максимальной. Записав необходимое условие существования экстремума (max), получаем уравнение:
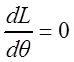 ,
(3.2)
,
(3.2)
которое называется уравнением правдоподобия.
Решение этого уравнения – ![]() называется оценкой наибольшего
правдоподобия.
называется оценкой наибольшего
правдоподобия.
Если закон распределения зависит не от одного, а от r параметров, рассуждая аналогично, получим систему уравнений (необходимое условие существования экстремума функции нескольких переменных).
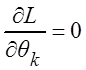 , k=
, k=![]() .
(3.3)
.
(3.3)
Функция L является произведением nфункций, а n , как правило, очень велико. Поэтому левые части уравнений (3.2) и (3.3), как правило, будут вычисляться очень сложно. Поэтому часто рассматривается логарифмическая функция правдоподобия
![]() = lnL=
= lnL=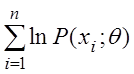
теперь это уже сумма ![]() слагаемых,
производная которой вычисляется значительно проще.
слагаемых,
производная которой вычисляется значительно проще.
В силу монотонности логарифмической
функции, точки экстремума функцийLи ![]() будут совпадать. Поэтому (3.2)
будут совпадать. Поэтому (3.2)
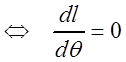 ; а (3.4)
; а (3.4)
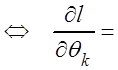 0 , k =
0 , k = ![]() .
.
Пример 3.7. По имеющейся случайной выборке ![]() , xi Î
N
, xi Î
N![]() {0} найти оценку
наибольшего правдоподобия для параметра l
случайной величины m,
распределённой по закону Пуассона:
{0} найти оценку
наибольшего правдоподобия для параметра l
случайной величины m,
распределённой по закону Пуассона: 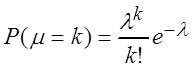 .
.
Решение. Строим функцию правдоподобия:
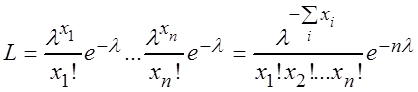 ;
; 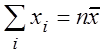 .
.
Обозначим 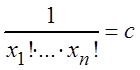 ,
тогда
,
тогда
L = c![]() ,
, 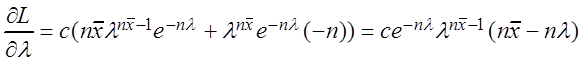 ,
,
(3.3) ![]() ,
отсюда
,
отсюда ![]() .
.
Если ![]() -
непрерывная случайная величина, то в этом случае функция правдоподобия
определяется из равенства:
-
непрерывная случайная величина, то в этом случае функция правдоподобия
определяется из равенства:
L(x1, ..., xn; q)D x1 . . . D xn = f(x1; q)Dx1 . . . f(xn; q)Dxn ,
в правой части которого вероятность того, что многомерная
случайная величина ![]() = (x1, ..., xn) примет значение из параллелепипеда со
сторонами: Dx1, Dx2, ..., Dxn. Из
этого равенства находим L = f(x1; q) ...
f(xn; q) , т.е. функция правдоподобия
пропорциональна вероятности реализации выборки, значит и для непрерывной
случайной величины справедливы ранее записанные уравнения
(3.2), (3.3).
= (x1, ..., xn) примет значение из параллелепипеда со
сторонами: Dx1, Dx2, ..., Dxn. Из
этого равенства находим L = f(x1; q) ...
f(xn; q) , т.е. функция правдоподобия
пропорциональна вероятности реализации выборки, значит и для непрерывной
случайной величины справедливы ранее записанные уравнения
(3.2), (3.3).
Пример 3.8. Найти оценки наибольшего правдоподобия m, s нормального распределения.
Решение. Пусть q1 = m, q2 = s, 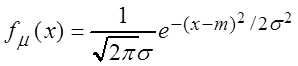 .
.
![]()
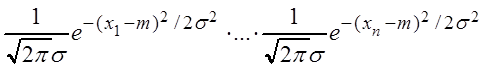
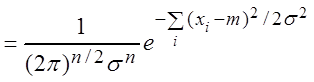 ,
,
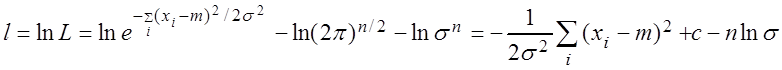 ,
,
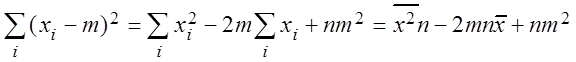 .
.
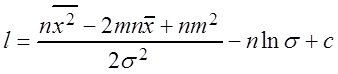 ,
,
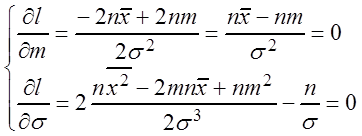 , m
=
, m
= ![]() ,
, 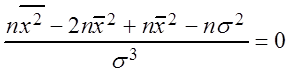 ,
,
![]() ,
, ![]()
![]() .
.
Таким образом, ![]() ,
, ![]() .
.
Оценки наибольшего правдоподобия всегда являются состоятельными и эффективными.
3.4. Проверка статистических гипотез
3.4.1. Основные понятия
Любое предположение, основанное на
результатах анализа случайной выборки ![]() относительно
теоретической функции распределения, называется статистической гипотезой
(или гипотезой).
относительно
теоретической функции распределения, называется статистической гипотезой
(или гипотезой).
Например, в схеме Бернулли:
1) вероятность появления события А в отдельном испытании равна 0,4,
2) вероятность появления события А в отдельном испытании р> 0,7,
3) вероятность появления события А в отдельном испытании 0,3 < p < 0,4
или в общем случае;
4) случайная величина m распределена по нормальному закону с параметрами: m = 0, s = 1,
5) при нормальном законе распределения D(m) = s2£ M2(m),
6) случайная величина m распределена по показательному закону,
7) случайная величина распределена по показательному закону, параметр которого 1£ l£ 2.
Основная задача – по результатам случайной выборки определить: справедлива или несправедлива выдвинутая гипотеза.
С любой гипотезой можно рассматривать непересекающуюся гипотезу. Одна из них называется основной гипотезой – H0, вторая – конкурирующей или альтернативной – H1.
Это разделение условно. Обычно в качестве основной гипотезы принимается та, которая несёт больше информации о теоретической функции распределения.
Все гипотезы разделяются на простые и сложные.
Гипотезаназывается простой, если она полностью определяет теоретическую функцию распределения (в примере это гипотезы 1 и 4), все остальные гипотезы называются сложными.
Каждая из гипотез выделяет некоторый класс функций распределения.
Обозначим эти множества: F0 и F1, тогда:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.
 .
.