· зеркалирование серверов.
7.2.1. Отказоустойчивый кластер
В основе кластеризации лежит идея о полном дублировании сетевого сервера. Несколько серверов (в SQL Server 2005 – до четырех) объединяются в кластер и образуют один виртуальный сервер. Серверы кластера называются узлами. Контроль узлов кластера осуществляется службой Clustering Service операционной системы Windows. Пользователи не знают о существовании узлов кластера, им виден только виртуальный сервер.
Типичная структура кластера приведена на рис 7.1.
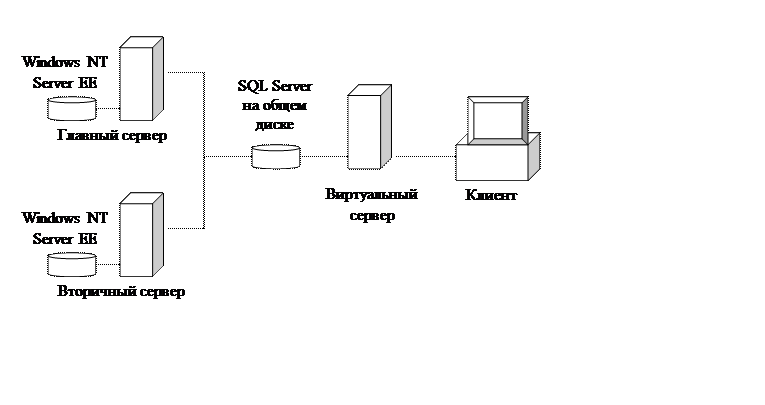
Рисунок 7.1 – Общая структура кластерных систем
Оба сервера используют общий диск для хранения данных. Основной сервер принимает запросы пользователей, выполняет их и осуществляет всю работу с общим диском. Служба Clustering Service отображает все выполняемые процессы с главного сервера на вторичный, она же производит мониторинг узлов и при выходе из строя одного из них переносит нагрузку на оставшийся сервер.
Благодаря такому подходу пользователям не требуется вручную переключаться с одного сервера на другой.
Необходимо отметить, что «узким местом» кластера является общий диск. В случае его физического повреждения БД окажутся недоступными. Поэтому вместо одного диска чаще используется массив дисков (RAID).
Технология RAID
RAID (Redundant Array of Independent Disks – избыточный массив независимых дисков) представляет собой технологию повышения отказоустойчивости жесткого диска. Основная идея состоит в том, что, собственно, вместо одного-единственного жесткого диска используется массив параллельно работающих дисков. Данные записываются на диски таким образом, что при выходе из строя одного из дисков информация может быть восстановлена с оставшихся дисков массива.
Различают шесть способов объединения дисков (RAID 0 – RAID 5) , но в Windows NT применяются только три: RAID 0, RAID 1 и RAID 5. В них наилучшим образом сочетаются производительность и надежность.
При использовании RAID-массивов для хранения файлов SQL Server 2005 вся работа по поддержанию файлов ложится на операционную систему. СУБД обращается к файлам в массиве RAID точно так же, как и к файлам, хранящимся на отдельном диске. Использование RAID-массивов в качестве общих дисков при кластеризации гарантирует работу системы даже при выходе из строя диска, а не сервера СУБД.
Принципы работы уровней RAID 0, RAID 1 и RAID 5 сводятся к дублированию и чередованию дисков.
Дублирование дисков лежит в основе уровня RAID 1. Массив на этом уровне составляется из двух дисков: основного (оригинального) и теневого. Операционная система работает с основным диском. Все изменения, выполненные на основном диске, автоматически отображаются на теневой диск, и в результате получаются две идентичные копии данных.
Дублирование дисков чаще всего реализуется аппаратно. Диски могут быть подключены к одному контроллеру, который выполняет все действия по поддержке дискового массива, снимая нагрузку с операционной системы. Недостатком такого подхода является низкая скорость записи данных. Кроме того, при выходе из строя контроллера оба диска оказываются недоступными. Поэтому известен и другой вариант реализации RAID 1: подключение дисков к разным контроллерам. В этом случае управление дисковым массивом берет на себя операционная система.
Чередование дисков используется на уровнях RAID 0 и RAID 5. Чередующийся набор дисков представляет собой совокупность множества физических дисков, объединенных в один виртуальный том. Размер и модели дисков могут быть различны, но для построения RAID на каждом диске выделяется пространство одинакового размера. Максимальный размер виртуального тома равен размеру самого малого диска, умноженному на количество дисков в наборе. Пространство физического диска, используемое для создания массива, называется слоем.
На рис. 7.2 изображена схема разбиения слоев на блоки и объединения блоков в полосы. Размер одного блока равен 64 Кбайт. Блоки нумеруются последовательно от начала слоя. Каждая полоса содержит по одному блоку из каждого слоя. Номера блоков в одной и той же полосе одинаковы. Полосы нумеруются в соответствии с номерами своих блоков.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.