






Итерационные алгоритмы порогового декодирования
Рассмотрим возможные варианты реализации итерационных пороговых алгоритмов декодирования сверточных кодов, позволяющие либо улучшить качество декодирования (получить энергетический выигрыш) в каналах низкого качества, либо увеличить вычислительную скорость декодирования.
Основными алгоритмами итерационного порогового декодирования сверточных кодов являются непрерывный и блочный алгоритмы. Они различаются тем, что непрерывный декодер в процессе анализа синдрома ошибки сохраняет все связи между элементами синдрома независимо от номера итерации и реализацией процесса декодирования: посимвольно или поблочно. Блочный декодер выполняет все итерации декодируемого блока, прежде чем начинается декодирование следующего блока, в результате ненулевые символы синдрома, обусловленные ошибками в последующем блоке, не корректируются обратной связью и могут стать причиной ложной коррекции ошибок («граничный эффект»).
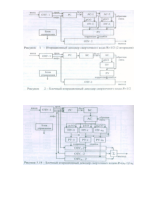
Рассмотрим работу непрерывного и блочного декодеров на примере свёрточного кода R=1/2. Функциональные схемы декодеров для канала с жёстким решением приведены на рисунках 1 и 2.
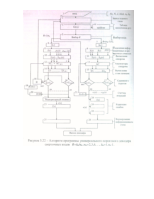
Декодируемый блок двоичных символов (в непрерывном декодере это может быть один кадр) кода записывается в оперативное запоминающее устройство (накопитель канала) ОЗУ-1; на выходе ОЗУ-1 символы разделяются на информационные и проверочные. Информационные символы записываются в накопитель ОЗУ-2, емкость которого у непрерывного декодера должна быть равна (у+1)*k , а у блочного декодера – 2k, где у- число итераций, k- число информа- ционных символов в декодируемом слове. Кроме того, информационные и проверочные символы поступают в регистр синдрома (РС), где вычисляется синдром ошибки .S(x), который в непрерывном декодере подаётся в анализатор синдрома АС-1 или в блочном декодере через буфер синдрома (БС) в АС; БС используется для хранения и коррекции синдрома ошибок следующего блока в процессе итераций.
Пороговые устройства (ПУ) в соответствии с производящим многочленом g(х) определяют вес проверки В, для каждого информационного символа r декодируемого блока на каждой итерации у
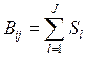
и сравнивают его с уровнем порога Ту.
Если Bij > Ту, то ошибка обнаружена, на выходе ПУ формируется символ "1" (иначе символ "0"), который по цепи обратной связи стирает синдром обнаруженной ошибки в АС и подаётся в решающее устройство (РУ) цепи коррекции ошибки. РУ на основе данных, полученных от ПУ после у итераций, выносит решение о необходимости коррекции i-го символа декодируемого блока, находящегося в ОЗУ-2. Когда декодирование всех символов блока заканчивается и они считываются из ОЗУ-2, из ОЗУ-1 в ОЗУ-2 записывается новый блок информационных символов, одновременно в РС формируется соответствующий синдром ошибок и так далее.
Непрерывный декодер для каждой итерации использует отдельный анализатор синдрома, блочному декодеру достаточно одного анализатора, но необходим БС для обеспечения непрерывности анализа синдромов ошибок соседних блоков. Блок управления обеспечивает временную синхронизацию (начало работы кодера и декодера должны совпадать с точностью до одного символа кода) и управление режимами работы всех устройств декодера. Алгоритм работы этого блока существенно влияет на скорость работы всею декодера.
В отличие от непрерывного декодера длина декодируемого блока в блочном декодере не может быть произвольной, гак как это существенно влияетнавероятность ошибки декодирования
Если длина блока меньше длина кодового слова обратная связь в декодере используется не эффективно, не в полной мере используются свойства кода как сверточного; если nбл>n, вероятность ошибки декодирования медленно стремится к вероятности ошибки декодирования непрерывного декодера за счёт ослабления влияния "граничного эффекта" на стыке блоков, но слишком длинный блок усложняет реализацию декодера; лучше заменить код на другой с большим кодовым ограничением.
Следовательно, блочный пороговый декодер всегда хуже непрерывного по качеству декодирования, но лучше тем, что декодирование каждою следующего блока начинается в менее «засоренном» анализаторе синдрома, что способствует увеличению предельной вероятности Рп.
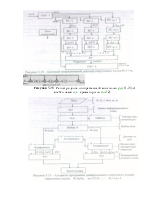
Однако, более эффективным методом увеличения предельной вероятности Pn, а следовательно и повышения энергетического выигрыша кода в каналах низкого качества, является изменение уровня порога на итерациях. Каким должен быть уровень порога на каждой итерации, можно определить по спектру весов проверок Bi,y.
Анализируя множество весов и распределение их вероятностей Р(Bi,y),
можно заметить следующее.
1 В множестве весов проверок наблюдаются все значения Bi,y в интервале от 0 до J как в канале с независимыми ошибками, так и с пакетами ошибок; при малом числе ошибок в блоке распределение вероятностей весов двухмодально, при большом числе ошибок - одномодально, исчезают нулевые и большие веса, близкие к J, среднее значение веса проверок увеличивается, причём такое сочетание ошибок, как правило, не исправляется. Поэтому эти свойства распределения весов проверок могут использоваться для отказа от декодирования и формирования соответствующего сигнала стирания.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.