Кроме того, разделенные последовательности Р(х) и //д) поступают в регистр синдрома (РС), в котором вычисляется общий синдром ошибки
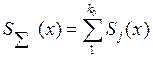
в соответствии с порождающими многочленами данного кода: g1(х). gk0(х).
В буфере синдрома(БС) и анализаторе синдрома(АС) производится поэлементный анализ синдрома и для каждого символа информационных последовательностей 1j(х), расположенных в ОЗУ -2 , вычисляется сумма проверок в соответствии с видом порождающего многочлена gj(х). В пороговых устройствах ПУ-j (j= 1 . . k0) обнаруживается ошибка и через соответствующее решающее устройство (РУ-i) производится коррекция информационного символа в ОЗУi -2 и синдрома ошибки, находящегося в АС. Если ошибки имели место, то в блоке управления формируется команда "повторить декодирование" данного блока (выполнить еще одну итерацию), по этой же команде могут быть изменены уровни порогов в ПУ. Буфер синдрома (БС) необходим для хранения остатка синдрома ошибки после декодирования данного блока, этот остаток используется (с учетом непрерывности кода) для декодирования следующего блока.
После завершения декодирования данною блока информационные последовательности: I(х)... 1k0(х) суммируются и поступают па выход декодера.
Аналогичным образом работает блочный итерационный пороговый декодер и для сверточных кодов R=1/n0, структурная схема которого показана на рисунке 5.19. Отличие в том, что теперь на выходе ОЗУ-1 образуется одна информационная последовательность 1(х) и (n0-1) проверочных последовательностей: Р1(х) . . . Рn0-1(х) , соответственно имеется (п0-1) регистров синдрома (РС-1 . . . РС-n0-1). буферных регистров (БС-1 . . . БС-по-1) и анализаторов синдрома (АС-1... АС-по-1).
Коррекция ошибок производится всеми пороговыми устройствами в одном ОЗУ-2 информационных символов через решающее устройство (РУ), которое содержит правило решения о необходимости коррекции данного информационного символа по (n0-1) выходам пороговых устройств и у итерациям. Эmо может быть, например, мажоритарное правило решения, учитывающее не только состояние выходов пороговых устройств, но и номер итерации.
Реализация пороговых декодеров сверточных кодов
Создание декодеров сверточных кодов исторически начато со сложных декодеров с хорошими характеристиками в 60-х годах двадцатого столетия, затем в 70-х годах были разрабomаны более простые декодеры Фано и Витерби для сверточных кодов с малым кодовым ограничением. Было показано, что при любых скоростях передачи, меньших пропускной способности канала, существует код и метод декодирования, обеспечивающие экспоненциальное убывание вероятности ошибки при среднем числе вычислительных операций на символ (вычислительной скорости), ограниченном постоянной, не зависящей от длины кода п. Учитывая также необходимость применения кодов с большим кодовым ограничением, процесс поиска алгоритмов реализации пороговых декодеров сверточных кодов должен ограничиваться такими структурами, которые обеспечивают возможно малую вычислительную скорость (или вычислительную сложность).
Схемы декодеров, показанные на рисунках 5.11, 5.12, 5.18, 5.19, могут быть реализованы непосредственно на регистрах сдвига и логических структурах малой и средней степени интеграции. Для регистров РС, АС и БС могут быть использованы специальные БИС, так как эти регистры имеют практически одинаковую структуру, которая определяется видом производящего (производящих) многочлена (ов) кода и показана на рисунке 5.20. Регистр РС отличается от АС и БС только тем, что в РС на вход 1 сумматоров подается очередной информационный символ ui, а в регистр АС и БС - результат решения ПУ, поступивший по цепи обратной связи (ОС). На вход 2 регистра в режиме АС и БС подаются элементы синдрома с выхода РС или АС соответственно, а в режиме РС - вход 2 отключен.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.