In the present case, the selection of the
smoothing constant for a nondaily series will be based on a time domain
methodology that produces an equivalent constant, in the sense of producing the
same percentage of smoothness as that obtained with a daily series. We start by
considering the type of aggregation that links a lower-frequency series ![]() with a
higher-frequency series {Yt}. The aggregation is assumed
to be linear, that is
with a
higher-frequency series {Yt}. The aggregation is assumed
to be linear, that is
k
YT∗ = cjYk(T−1)+j for T =1,...,n (19) j=1
with n=N/k, where x denotes the integer part of a real number x, and k is the number of observations Yt between two successive observations YT∗. The cjs are constants that define the type of aggregation, e.g. c1=···=ck =1 are used to aggregate a flow series and c1=···=ck =1/k are used when working with an index or an annualized flow series (which is also considered a flow series). When working with a series of stocks, the aggregated series is generated by systematic sampling. In that case the usual values are c1=1, c2=···=ck =0 or c1=···=ck−1=0, ck =1.
Without loss of generality, in what follows we shall assume that c1=···=ck =1 for a flow series and c1=···=ck−1=0, ck =1 for a series of stocks. Thus, let T and t be the time sub-index for the aggregated and disaggregated series, respectively, then we have
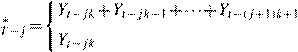 for flows
for flowsY, j =0,1,...,T −1 (20) for stocks
The model to be applied to the aggregated data preserves the form (12)–(13), in particular the order of integration (as shown by Brewer [17]), that is,
Y∗ =s∗+g∗ with E(g∗)=0, Var(g∗)=∗2In (21)
K1ns∗ =e∗ with
E![]() (22)
(22)
and E ![]() 0, where ∗ is used to denote aggregated
variables. As with (15), the trend estimator is given by
0, where ∗ is used to denote aggregated
variables. As with (15), the trend estimator is given by
sˆ∗ ![]() 1∗− 2Y∗ (23)
1∗− 2Y∗ (23)
Even though expressions (15) and (23) are of the same form,
the resulting trends are different. In fact, aggregating the trend ![]() estimated from the
disaggregated series will produce different values than those of the estimated
trend
estimated from the
disaggregated series will produce different values than those of the estimated
trend ![]() obtained directly
from the aggregated series. Nevertheless, we show below that it is possible to
find a smoothing constant for
a disaggregated series that is equivalent to the ∗k value
for the aggregated data, in the sense of producing the same percentage of
smoothness.
obtained directly
from the aggregated series. Nevertheless, we show below that it is possible to
find a smoothing constant for
a disaggregated series that is equivalent to the ∗k value
for the aggregated data, in the sense of producing the same percentage of
smoothness.
From Equations (21)–(22) it follows that
![]() ∗∗T (24)
∗∗T (24)
where ∇∗ is
the difference operator for the aggregated series, so that ![]() is represented by
an IMA(1,1), i.e. an Integrated Moving Average model of
order (1,1) whose variance ∗0 and
autocovariance ∗1
are given by
is represented by
an IMA(1,1), i.e. an Integrated Moving Average model of
order (1,1) whose variance ∗0 and
autocovariance ∗1
are given by
![]() ∗2
and ∗1=−∗2 (25)
∗2
and ∗1=−∗2 (25)
Similarly, from Equations (12)–(13) we know that the
disaggregated series follows the IMA(1,1) model ![]() t with
variance
t with
variance ![]() and covariance 1=−2. To see how the
two IMA=(1+,1)+···+models relate to each other, let us first
consider a flow series, i.e. letk−1. Since Sk∇ we have YT∗−so thatj =SkY∇t−kjkSkwithYt
=
and covariance 1=−2. To see how the
two IMA=(1+,1)+···+models relate to each other, let us first
consider a flow series, i.e. letk−1. Since Sk∇ we have YT∗−so thatj =SkY∇t−kjkSkwithYt
=
S![]() Sk
Sk![]() T =∇ t we get
T =∇ t we get
![]() kt for
flows (26)
kt for
flows (26)
Now, for a stock series we know that Y![]() −j
t jk and
−j
t jk and![]() kYt
so that the previous derivation leads us to
kYt
so that the previous derivation leads us to
![]() kt for
stocks (27)
kt for
stocks (27)
![]()
![]()
![]() Therefore, the autocovariance generating function (AGF) of the
disaggregated series, (B)=
Therefore, the autocovariance generating function (AGF) of the
disaggregated series, (B)= ![]() j
Bj, is given by
j
Bj, is given by
(28) for stocks
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.