«Складывание» ![]() в
границах между подинтервалами может быть рассмотрено как разделение функции на
сегменты
в
границах между подинтервалами может быть рассмотрено как разделение функции на
сегменты
![]() .
.
Используя формулы (24), (25) и (26) каждый сегмент может быть представлен как суперпозиция ортогональных элементарных сигналов
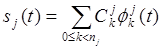 , где
, где ![]() - число отсчетов на интервале
- число отсчетов на интервале ![]() ;
;
![]() - спектральные коэффициенты, вычисленные с
помощью ДКП.
- спектральные коэффициенты, вычисленные с
помощью ДКП.
Анализ и синтез сигнала может быть представлен в виде следующей схемы (рис. 14).
Каждый коэффициент ![]() дискретного
локального косинусного преобразования представляет собой амплитуду
элементарного колебания. Его период
дискретного
локального косинусного преобразования представляет собой амплитуду
элементарного колебания. Его период ![]() , где
, где 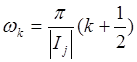 , следовательно, частота
, следовательно, частота
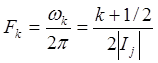 .
(28)
.
(28)
Максимальная частота, которая может быть
обнаружена, не превышает половину частоты дискретизации. Частота дискретизации
равна ![]() , следовательно
, следовательно
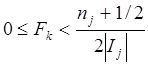 .
.
Если исходный сигнал дискретизирован равномерно на
интервале ![]() , тогда
, тогда ![]() будет
пропорционально длине подинтервала
будет
пропорционально длине подинтервала ![]() и, поэтому, все
подинтервала будут иметь одинаковую частоту дискретизации. Однако, так как
более короткие подинтервалы содержат меньшее коэффициентов, их частотное
разрешение будет ниже.
и, поэтому, все
подинтервала будут иметь одинаковую частоту дискретизации. Однако, так как
более короткие подинтервалы содержат меньшее коэффициентов, их частотное
разрешение будет ниже.
Для сжатия сигнала в пределах сегмента (подинтервала), введем формантное представление следующим образом. В каждом сегменте в спектре необходимо найти несколько самых крупных пиков и определить их положение. Если использовать для описания сегмента только параметры нескольких пиков, то это позволит значительно уменьшить количество данных, используемых для хранения сигнала или его последующего распознавания.
Основная частота речевого сигнала лежит в диапазоне
140..250 Гц для женского голоса и 100..150 Гц для мужского, то есть ниже 250
Гц. Зная частоту дискретизации, можно определить номер гармоники ![]() , соответствующей максимальной основной
частоте голосового сигнала, и ввести критерий для различения речевого и
неречевого сегментов сигналов.
, соответствующей максимальной основной
частоте голосового сигнала, и ввести критерий для различения речевого и
неречевого сегментов сигналов.
Определить индекс частоты ![]() и
величину самой большой спектральной компоненты можно по следующей формуле
и
величину самой большой спектральной компоненты можно по следующей формуле
![]() .
(29)
.
(29)
Частота ![]() называется первой
основной частотой спектра сигнала. Если
называется первой
основной частотой спектра сигнала. Если ![]() - то
сигнал в сегменте
- то
сигнал в сегменте ![]() называется голосовым, и не
голосовым в противоположном случае.
называется голосовым, и не
голосовым в противоположном случае.
Для более качественного и более сложного распознавания, можно использовать более одной частоты для описания спектра в сегменте. Для нахождения второй основной частоты при известной первой, необходимо убрать все коэффициенты вблизи первой частоты и найти самый большой из оставшихся.
Рассмотрим для примера сигнал ![]() на интервале
на интервале![]() , найдем
для него первые две основные частоты
, найдем
для него первые две основные частоты ![]() и
и ![]() .
.
Сначала вычисляется ![]() из
(29), затем обнуляются коэффициенты
из
(29), затем обнуляются коэффициенты ![]() , если
, если ![]() , где
, где ![]() -
заданный порог, указывающий какое число соседних коэффициентов необходимо
обнулить. Этот параметр определят минимальное расстояние между пиками, при
котором они могут быть различены. Затем находится
-
заданный порог, указывающий какое число соседних коэффициентов необходимо
обнулить. Этот параметр определят минимальное расстояние между пиками, при
котором они могут быть различены. Затем находится ![]() из
следующего равенства
из
следующего равенства
![]() .
.
Эту операцию можно повторять до тех пор, пока есть ненулевые
коэффициенты ![]() . Для ускорения завершения алгоритма, можно
использовать
. Для ускорения завершения алгоритма, можно
использовать ![]() % энергии спектра, и в этом случае
сравнительно маленькие пики не будут обнаруживаться как основные частоты.
Параметрами алгоритма, таким образом, будут
% энергии спектра, и в этом случае
сравнительно маленькие пики не будут обнаруживаться как основные частоты.
Параметрами алгоритма, таким образом, будут ![]() и
и ![]() , которые можно выбрать эмпирически.
Следует заметить, что их величина зависит от заданного отношения сигнал шум.
, которые можно выбрать эмпирически.
Следует заметить, что их величина зависит от заданного отношения сигнал шум.
Коэффициенты ![]() вблизи
пиков несут некоторую дополнительную информацию. Для её учета можно
использовать понятие центральной частоты, соответствующей каждой основной
частоте
вблизи
пиков несут некоторую дополнительную информацию. Для её учета можно
использовать понятие центральной частоты, соответствующей каждой основной
частоте ![]()
![]() , где
, где
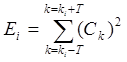 и
и 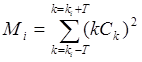 , для
, для ![]() .
.
В этом случае каждая основная частота ![]() описывается формантой в виде парой
описывается формантой в виде парой ![]() (положение центра масс пика и энергия
пика). Формантное представление для речевого сигнала состоит из списка интервалов
вместе с несколькими формантами с наибольшей энергией. Эти данные могут быть
использованы как для сжатия, так и для распознавания речи.
(положение центра масс пика и энергия
пика). Формантное представление для речевого сигнала состоит из списка интервалов
вместе с несколькими формантами с наибольшей энергией. Эти данные могут быть
использованы как для сжатия, так и для распознавания речи.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.