Вычисление стандартного отклонения для выборки
Для того чтобы найти стандартное отклонение для выборки, необходимо выполнить следующие действия.
1. Найти отклонения, вычитая из каждого значения среднее.
2. Возвести полученные значения в квадрат, сложить и разделить полученную сумму на n - 1. Результатом будет дисперсия.
3. Извлечь из полученного значения квадратный корень. Это и будет стандартное отклонение.
Формула для вычисления стандартного отклонения является краткой математической записью описанной выше процедуры. Стандартное отклонение для выборки данных обозначается буквой S, и формулы вычисления стандартного отклонения и дисперсии имеют следующий вид.
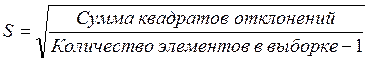
или
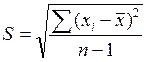
Стандартное отклонение имеет простую и понятную интерпретацию: эта величина описывает типичное расстояние от среднего значения для отдельных значений набора данных. Таким образом, стандартное отклонение выступает в качестве меры изменчивости для этих отдельных значений. Поскольку стандартное отклонение отражает типичную величину отклонения, то можно предположить, что для одних значений отклонение будет меньше стандартного, а для других — больше.
Пример. Учет различий между клиентами
Ваши клиенты отличаются друг от друга; между ними существуют различия в размерах заказов, предпочтении различных товаров, цикличности работы в течение года, потребности в информации, приверженности работе с вами и т.п. Однако у вас, видимо, есть определенное суждение о "типичном клиенте", а также некоторое представление о степени различий между клиентами.
Вы можете обобщить информацию о заявках клиентов с помощью среднего и стандартного отклонения.
|
Общий годовой объем заказа на одного клиента |
|
|
Среднее значение |
$85600 |
|
Стандартное отклонение |
$28300 |
Таким образом, за последний год каждый клиент в среднем заказал товаров на сумму $85600. В качестве характеристики различий между клиентами выступает стандартное отклонение. Его величина в $28300 показывает, что обычно ваши клиенты делали заказы на суммы, меньшие или большие примерно на $28300, чем среднее значение в $85600. Слово "примерно" имеет здесь большое значение: некоторые клиенты могут делать заказы, размер которых очень близок к среднему уровню, в то время как для других будут наблюдаться отличия, значительно превышающие $28300. Среднее значение показывает типичный объем поступивших в течение года заказов от одного клиента, а стандартное отклонение иллюстрирует типичное отклонение от среднего.
Обратите внимание также на то, что стандартное отклонение измеряется в тех же единицах, что и среднее значение; в данном случае обе эти величины определены в долларах. Если говорить точнее, то единица измерения здесь — это "доллар в год на одного клиента". Это увязывает единицы измерения с исходным набором данных, который представляет собой последовательность объемов "долларов в год", причем каждому клиенту соответствует одно число.
Интерпретация стандартного отклонения для нормального распределения
В том случае, когда набор данных имеет приблизительно нормальное распределение, стандартное отклонение приобретает особый смысл. Приблизительно две трети значений из такого набора данных находятся в пределах одного стандартного отклонения по обе стороны от среднего значения. Около 95% всех значений находятся в пределах двух стандартных отклонений от среднего. И, наконец, мы можем ожидать, что обнаружим почти все данные (99,7%) на расстоянии не более трех стандартных отклонений от среднего.
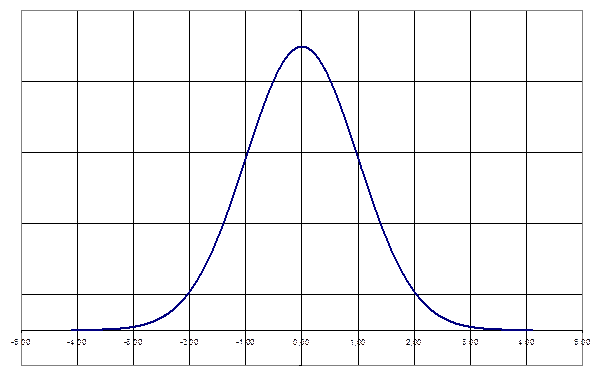
Так, например, если способности ваших работников распределены приблизительно нормально, то вы можете ожидать, что оценки способностей примерно двух третей из них попадают на расстояния не более одной величины стандартного отклонения от среднего значения — либо выше, либо ниже среднего. Это означает, что приблизительно треть работников имеет способности, лежащие в пределах одной величины стандартного отклонения выше среднего, а примерно треть — в соответствующей области ниже среднего. Остальные работники, которых также приблизительно треть, распределятся таким образом: около половины этой одной трети (шестая часть всех работников) обладает способностями, превышающими средние более чем на величину одного стандартного отклонения, и примерно шестая часть всех работников (увы!) окажется ниже среднего далее, чем на расстоянии одного стандартного отклонения.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.