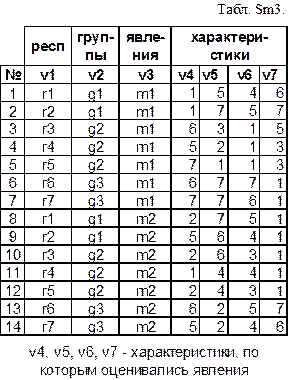 Sm3. Различия между 2-мя группами (использование
условий отбора)
Sm3. Различия между 2-мя группами (использование
условий отбора)
Просмотрите исходные данные в табл. Sm3. Несколько респондентов (их обозначения содержатся в переменной v1), распределенные по 3-м группам (обозначения групп содержатся в переменной v2), оценивали 2 явления (обозначения явлений содержатся в переменной v3) по нескольким характеристикам (оценки по этим характеристикам в 7-балльной шкале содержатся во всех остальных переменных табл.Sm3).
Введите в таблицу *.sta программы STATISTICA все данные о группах и явлениях, т.е. 14 строк и 2 столбца. Просмотрите в табл. «Варианты Sm3» обозначения двух характеристик «v», соответствующих вашему варианту. Добавьте в таблицу *.sta оценки по этим двум характеристикам. В итоге все ваши исходные данные в таблице *.sta должны занимать 14 строк и 4 столбца. Кстати, все эти данные уже содержатся в файле Sm3.sta. Но, даже если Вы найдете этот файл, проверьте его на соответствие с табл.Sm3, поскольку его могли изменить другие пользователи.
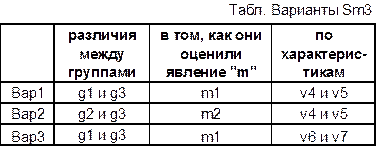 Вам необходимо проверить различия
между 2–мя группами в том, как они оценили одно явление. Между какими именно
группами и какое именно явление? Просмотрите это в таблице «Варианты Sm3» рядом с номером вашего варианта. Какое обозначение имеет
явление, указанное в вашем варианте? Чтобы объяснить задание, давайте временно
присвоим этому явлению обозначение «m». Обратите
внимание, что ваш файл *.sta содержит не только оценки
явления «m», но также и оценки второго явления, которое
не указано в вашем варианте. Так и должно быть: файл должен содержать все
данные, а Вы должны уметь использовать условия отбора. По этой же причине ваш
файл *.sta содержит данные о трех группах, хотя вас
сейчас интересуют только две группы.
Вам необходимо проверить различия
между 2–мя группами в том, как они оценили одно явление. Между какими именно
группами и какое именно явление? Просмотрите это в таблице «Варианты Sm3» рядом с номером вашего варианта. Какое обозначение имеет
явление, указанное в вашем варианте? Чтобы объяснить задание, давайте временно
присвоим этому явлению обозначение «m». Обратите
внимание, что ваш файл *.sta содержит не только оценки
явления «m», но также и оценки второго явления, которое
не указано в вашем варианте. Так и должно быть: файл должен содержать все
данные, а Вы должны уметь использовать условия отбора. По этой же причине ваш
файл *.sta содержит данные о трех группах, хотя вас
сейчас интересуют только две группы.
sm 3.1. Условие отбора
Использование условий отбора сейчас связано с несколько более сложной, чем обычно, структурой исходных данных. Вы видите, что каждая группа оценивала два явления. Но нас интересуют различия между группами только в том, как они оценили явление «m», т.е. сейчас необходимо отобрать для анализа только те наблюдения (строки), которые относятся к явлению «m». Причем это надо сделать именно с помощью условий отбора.
Заголовки столбцов в таблице STATISTICA состоят из двух частей: из номеров (1,2,3,… и т.д.) и из имен переменных. Выполните двойной щелчок по заголовку какой-нибудь переменной. Обратите внимание, что в верхней части открывшегося окна указан номер переменной, начинающийся со слова «Variable», а в поле “Name” содержится имя переменной. Измените это имя (можете сейчас использовать любое короткое обозначение) и нажмите Ok. Вы видите, что Вы изменили имя переменной, но ее номер остался прежним. Это номер по порядку. Изменить его Вы не можете. В условиях отбора используются именно номера, но не имена переменных. Допустим, согласно вашему варианту, Вас интересуют оценки только явления «m2». Тогда, если ориентироваться на табл.Sm3, ваше условие отбора будет выглядеть так: v3=“m2”. В этом условии отбора после буквы «v» указан порядковый номер переменной, в которой содержатся обозначения явлений. Какой номер имеет эта переменная в вашем файле *.sta?
Итак, мы разобрались с тем, как необходимо записывать условие отбора. Теперь разберемся с тем, в каком окне его необходимо записывать. Откройте окно Tools|Selection conditions|Edit…, включите флажок Enable selection conditions и переключатель Specific, selected by: Введите условие отбора в поле Expression. И, хотя это и необязательно, давайте сделаем результат отбора хорошо заметным. Перейдите на вкладку Display, включите флажок Use specified format to identify…, нажмите кнопки Edit format… и Edit…, перейдите на вкладку Font и измените цвет текста Text color, например, сделайте его ярко-синим. Т.к. основной текст в таблице скорее всего черный, то ярко-синий будет хорошо виден. Подтвердите все изменения: Ок, Ок, Ок. Просмотрите ваш файл *.sta: теперь Вы хорошо видите те наблюдения, которые отобраны для анализа.
sm 3.2. Представление различий на Box-диаграммах
Хотя диаграммы
не позволяют принимать решение об отклонении (либо о неотклонении) нулевой
гипотезы ![]() , но они являются более наглядными, чем
таблицы. Поэтому разбираться со статистическими методами лучше начинать с
диаграмм.
, но они являются более наглядными, чем
таблицы. Поэтому разбираться со статистическими методами лучше начинать с
диаграмм.
Порядковые и метрические шкалы
Если метод предназначен для метрических шкал, а наши переменные измерены в порядковой шкале, то это может привести к некорректной интерпретации. Но, если мы это понимаем и используем диаграммы только для наглядного представления различий и не более того, то ничего некорректного в наших действиях нет.
Группирующая и зависимые переменные
В качестве группирующей используется та переменная, которая содержит обозначения сравниваемых групп. В таблице Sm3 группирующая переменная – v2. Какое имя имеет группирующая переменная в вашем файле *.sta?
В качестве зависимых переменных Вы будете использовать характеристики, по которым оценивались явления. Таких характеристик у вас сейчас две: их обозначения даны в таблице «Варианты Sm3» рядом с номером вашего варианта. Вы уже ввели оценки по зависимым переменным в ваш файл *.sta, они занимают 2 столбца. Какие имена имеют зависимые переменные в вашем файле *.sta?
Построение Box-диаграмм:
Выполните инструкции «s6» и вернитесь сюда (в данную точку инструкций “sm”) снова.
Анализ Box-диаграмм:
Просмотрите все графики с помощью списка в левой части окна. Для каждой зависимой переменной программа построила отдельный график. Количество Box-диаграмм на каждом графике равно количеству сравниваемых групп. Вас сейчас интересуют только 2 группы. Какое количество наблюдений соответствует каждой из этих двух групп? Иначе говоря, сколько респондентов в каждой из этих 2-х групп оценивали явление «m»?
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.

