Помехоустойчивое кодирование данных при передаче по каналам связи относится к классу косвенных методов защиты от ошибок и является альтернативой основному пути защиты – созданию более помехоустойчивого канала. Такой подход обусловлен экономическим выигрышем.
Перечислим основные характеристики, по которым мы
судим об их потенциальных возможностях. Есть коды блоковые и древовидные.
Кодирование блоковым кодом это отображение пространства информационных
последовательностей длины ![]() над
над ![]() - ичным алфавитом
- ичным алфавитом ![]() в пространство избыточных кодовых
последовательностей длины
в пространство избыточных кодовых
последовательностей длины ![]()
![]() . Отношение
. Отношение ![]() называется
скоростью кода. На практике интерес представляют высокоскоростные коды, для
которых избыточность оказывается небольшой (
называется
скоростью кода. На практике интерес представляют высокоскоростные коды, для
которых избыточность оказывается небольшой (![]() -
число избыточных символов). Часто код называют исправляющим или обнаруживающим
ошибки. Это не совсем корректно. Код всегда один – избыточный, а избыточность
можно использовать или только для обнаружения ошибок, или только для
исправления, или комплексно – для исправления одних конфигураций ошибок и
обнаружения других. Важнейшей характеристикой кода является кодовое расстояние
-
число избыточных символов). Часто код называют исправляющим или обнаруживающим
ошибки. Это не совсем корректно. Код всегда один – избыточный, а избыточность
можно использовать или только для обнаружения ошибок, или только для
исправления, или комплексно – для исправления одних конфигураций ошибок и
обнаружения других. Важнейшей характеристикой кода является кодовое расстояние ![]() . Это минимальное число позиций, в
которых кодовые слова различаются друг от друга. Для линейного кода
. Это минимальное число позиций, в
которых кодовые слова различаются друг от друга. Для линейного кода ![]() совпадает с минимальным весом
кодовых комбинаций. Кратность исправляемых ошибок
совпадает с минимальным весом
кодовых комбинаций. Кратность исправляемых ошибок ![]() связана
с кодовым расстоянием соотношением
связана
с кодовым расстоянием соотношением ![]() , в случае
обнаружения -
, в случае
обнаружения - ![]() , в комплексном варианте
, в комплексном варианте ![]() . Спектром кода называют таблицу, в
которой приведены возможные расстояния между кодовыми словами и их частота
(вес). Первая строка с ненулевым весом дает значение
. Спектром кода называют таблицу, в
которой приведены возможные расстояния между кодовыми словами и их частота
(вес). Первая строка с ненулевым весом дает значение ![]() .
Если нет слов какого-либо веса, то это означает, что любая ошибка такой
кратности может быть обнаружена.
.
Если нет слов какого-либо веса, то это означает, что любая ошибка такой
кратности может быть обнаружена.
Как ясно из предыдущего, кодирование блоковым кодом
есть шифрование, составление таблицы «что есть что». Это простая по форме
задача для высокоскоростных кодов становится проблемной, так как даже для
двоичных кодов, если ![]() бит таблица кодирования не
реализуема ни по времени, ни по памяти. Вторая непростая задача заключается в
выборе метрики кода, согласованной с потоком ошибок канала. Очевидно,
последовательность длины
бит таблица кодирования не
реализуема ни по времени, ни по памяти. Вторая непростая задача заключается в
выборе метрики кода, согласованной с потоком ошибок канала. Очевидно,
последовательность длины ![]() из нулей и
единиц, которая часто возникает из-за помех в канале связи нерационально
выбирать в качестве кодовой комбинации. Следовательно, надо упорядочить
варианты ошибок по вероятности их возникновения, что предполагает нахождение
модели потока ошибок адекватно описывающих дискретный канал.
из нулей и
единиц, которая часто возникает из-за помех в канале связи нерационально
выбирать в качестве кодовой комбинации. Следовательно, надо упорядочить
варианты ошибок по вероятности их возникновения, что предполагает нахождение
модели потока ошибок адекватно описывающих дискретный канал.
Еще большие трудности возникают при декодировании,
которое эквивалентно разбиению пространства из ![]() последовательностей
на
последовательностей
на ![]() областей, отождествляемых с тем или
иным информационным блоком. Число областей может быть на единицу больше числа кодовых
слов, если допускается «стирание» - отказ от декодирования.
областей, отождествляемых с тем или
иным информационным блоком. Число областей может быть на единицу больше числа кодовых
слов, если допускается «стирание» - отказ от декодирования.
Каким же образом могут быть решены задачи кодирования и декодирования? Ответ один – необходимо использовать математическую теорию как для нахождения кодов с нужными свойствами, так и для построения технически осуществимых способов кодирования и декодирования. Математический аппарат для блоковых кодов это линейная алгебра (группа, кольцо, поле, линейное пространство – понятия алгебры, на основе которых строятся коды, кодеры и декодеры).
Другой вариант помехоустойчивого кодирования
древовидным кодом в отличие от блокового кода не предполагает жесткого деления
информационных бит на порции, передаваемые независимо. Порция данных гораздо
меньшего объема ![]() , называемая обычно информационным
кадром, превращается в кадр кодовый
, называемая обычно информационным
кадром, превращается в кадр кодовый ![]() (
(![]() ), но реакция на конкретный кадр
), но реакция на конкретный кадр ![]() будет разная в зависимости от того,
какими были предшествующие информационные кадры. Кодовое слово такого кода
получается полубесконечным, а код обладает памятью, с точки зрения теории
возможно и бесконечной.
будет разная в зависимости от того,
какими были предшествующие информационные кадры. Кодовое слово такого кода
получается полубесконечным, а код обладает памятью, с точки зрения теории
возможно и бесконечной.
Характеристиками древовидного кода будут: скорость ![]() , величина
, величина ![]() называемая
длиной кодового ограничения, здесь
называемая
длиной кодового ограничения, здесь ![]() - число
информационных кадров, предшествующих кодируемому и еще влияющему на результат
кодирования. Информационной длиной слова сверточного кода называют значение
- число
информационных кадров, предшествующих кодируемому и еще влияющему на результат
кодирования. Информационной длиной слова сверточного кода называют значение ![]() , кодовой длиной слова сверточного
кода называют
, кодовой длиной слова сверточного
кода называют ![]() .
.
Для практики наибольший интерес представляют
древовидные коды с конечной длиной кодового ограничения ![]() ,
постоянные во времени, линейные. Такие коды называются сверточными. Сверточный
код может быть как систематическим, так и несистематическим. Аналогом
характеристики спектр блокового кода является дистанционный профиль сверточного
кода. Свободной длиной
,
постоянные во времени, линейные. Такие коды называются сверточными. Сверточный
код может быть как систематическим, так и несистематическим. Аналогом
характеристики спектр блокового кода является дистанционный профиль сверточного
кода. Свободной длиной ![]() сверточного кода
называется длина имеющего наименьший вес ненулевого начального сегмента кодовой
последовательности сверточного кода.
сверточного кода
называется длина имеющего наименьший вес ненулевого начального сегмента кодовой
последовательности сверточного кода.
Это простейший код, который позволяет обнаруживать
все одиночные ошибки и все ошибки нечетной кратности. Код образуется путем
добавления к кодовой комбинации из k -
элементов, еще одного элемента, так чтобы в новой ![]() -разрядной
кодовой комбинации число единиц было всегда четным.
-разрядной
кодовой комбинации число единиц было всегда четным.
Эффективность этого кода целиком зависит от
статистики ошибок в канале связи. Действительно, ![]() ;
; ![]()
![]() .
.
![]() - вероятность неправильного приема
равна сумме вероятностей ошибок в кодовых комбинациях четной кратности. Чтобы
найти эти вероятности и оценить код, необходимо иметь модель потока ошибок в
дискретном канале связи.
- вероятность неправильного приема
равна сумме вероятностей ошибок в кодовых комбинациях четной кратности. Чтобы
найти эти вероятности и оценить код, необходимо иметь модель потока ошибок в
дискретном канале связи.
Код не защищает от групповых ошибок. Прием или неприем искаженной кодовой комбинации зависит от того «нужный» символ или нет стоит в последнем разряде. Но при групповой ошибке вероятность появления «0» или «1» равна ~ 0,5, т.е. в половине случаев условная вероятность комбинации быть принятой правильно тоже будет 0,5 при групповой ошибке.
Этот код в чистом виде, без комбинации с другими кодами, в настоящее время применяется очень редко. В ЭВМ ЕС байт защищается так именно. Достоинство этого кода – малая избыточность и простота реализации.
Типичный пример такого кода код МТК № 3-7
элементный, содержащий 3 единицы и 4 нуля в каждой кодовой комбинации. Всего
комбинаций ![]() , используется
, используется ![]() комбинаций. Коэффициент избыточности
комбинаций. Коэффициент избыточности
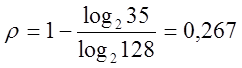 . Код позволяет обнаруживать все
одиночные, двойные, тройные и т.д. ошибки, кроме парных искажений, когда одна
«1» переходит в ноль, а один «0» переходит в «1», либо две «1» обращаются в
«0», и два «0» в «1» и т.д.
. Код позволяет обнаруживать все
одиночные, двойные, тройные и т.д. ошибки, кроме парных искажений, когда одна
«1» переходит в ноль, а один «0» переходит в «1», либо две «1» обращаются в
«0», и два «0» в «1» и т.д.
В основу построения кода положен метод повторения исходной кодовой комбинации. Однако в зависимости от четного или нечетного числа единиц в исходной комбинации последняя передается в неизменном виде, либо в инвертированном виде.
Пример.
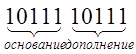 - четное число
единиц.
- четное число
единиц.
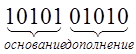 - нечетное число
единиц.
- нечетное число
единиц.
Декодирование производится следующим образом.
Сначала суммируются все «1» первой комбинации из ![]() разрядов.
Если их оказалось четное число, то вторые «п» разрядов без изменения
сравниваются поразрядно с первыми. Если число «1» в первой комбинации нечетные,
повтор ее инвертируется, а затем уже сравнивается. Если имеется хотя бы одно
несовпадение, все 2п элемента стираются (приема нет, ошибки обнаружены).
разрядов.
Если их оказалось четное число, то вторые «п» разрядов без изменения
сравниваются поразрядно с первыми. Если число «1» в первой комбинации нечетные,
повтор ее инвертируется, а затем уже сравнивается. Если имеется хотя бы одно
несовпадение, все 2п элемента стираются (приема нет, ошибки обнаружены).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.




