Кодирующее устройство
Пусть порождающий многочлен (n,k)-кода имеет вид:
g(x)=g0x0+g1x1+…+gn-kxn-k
В основе схем, реализующих кодирование по g(x), лежит схема деления на порождающий многочлен. Общий вид схемы кодера представлен на рис. 1:
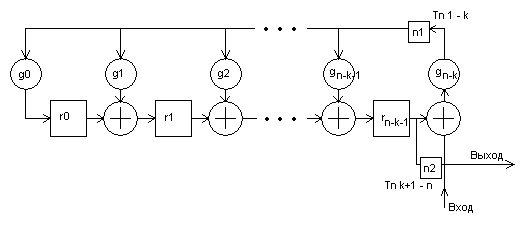 рис. 1
рис. 1
Здесь r0,r1,…,rn-k-1 – m-битовые регистровые ячейки, предназначенные для записи элементов поля GF(23); g0,g1,…,gn-k - умножители, соответствующие коэффициентам g(x); n1,n2 – ключи (n1 замкнут с 1-го по k-ый такт, n2 – с (k+1)-го по n-ый такт).
Алгоритм работы кодера:
1. На вход последовательно поступают информационные элементы, начиная со старшей степени. Благодаря тому, что вход подключен к регистру после последней (n-k)-ой регистровой ячейки достигается умножение кодируемой последовательности K(x) на xn-k;
2. За k тактов работы схемы производится деление входной последовательности K(x)*xn-k на g(x) и в регистровых ячейках формируются избыточные элементы;
3. С (k+1)-го по n-ый такт проверочные элементы последовательно выводятся из схемы. В результате на выходе кодера за n тактов работы схемы появляется комбинация кода Рида-Соломона f(x) с информационной частью K(x).
Декодирующее устройство
Для декодирования принятой последовательности будем использовать декодер вылавливания ошибок, схема которого для кода Рида-Соломона (7,3) изображена на рис. 2:
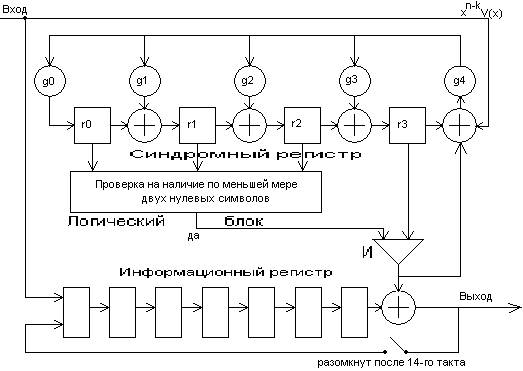 рис. 2
рис. 2
Автором метода вылавливания ошибок является Прейндж [1].
У кода Рида-Соломона (7,3) dmin=5, следовательно, он исправляет однократные и двукратные ошибки.
Декодер вылавливания ошибок исправляет ошибки последовательно за три 7-элементных цикла.
Декодер состоит из двух регистров – синдромного и информационного, логического блока и схемы И.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.