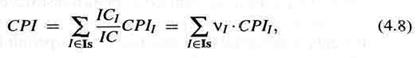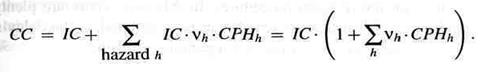aэти времена могут быть уменьшены до 89 использованием быстрой проверки на ноль для AEQZ
Согласно таблице 4.18, пересылка результата заметно замедляет окружение PC и выборку регистра операнда, увеличивая время цикла ядра DLX на 40%. Другие времена циклов остаются практически теми же самыми. Аппаратная взаимная блокировка делает механизм останова более сложным и увеличивает время цикла управления, но критичные по времени пути остаются такими же.
Значительное замедление, вызываемое пересылкой результата (result forwarding) не удивительно. В конструкции с основным конвейером вычисление ALU и обновление PC критично ко времени. С пересылкой результат ALU отправляется на этап ID и синхронизируется с регистром операнда Al и Bl. Это объясняет медленную выборку операнда. Результат пересылки также тестируется на ноль и сигнал AEQZ тогда подается на glue logic PCglueокружения PC. PCglueпредоставляет сигнал bjtaken, который управляет выбором нового программного счетчика. Таким образом, критичные по времени пути замедляются механизмом пересылки (6d), проверкой на ноль (9d), схемой PCglue (6d) и выбором PC (6d).
С использованием быстрой проверки на ноль из упражнения 4.6, время цикла может быть уменьшено на 4 вентильных задержки без дополнительной стоимости. Время цикла (89d) все еще на 35% выше, чем у основного конвейера. Однако, без пересылки и взаимной блокировки все опасности данных должны быть решены во время компиляции перестроением кода или вставкой команд NOP. Поэтому следующие разделы анализируют воздействие конвейеризации и пересылки на производительность команды и на отношение стоимость/производительность.
4.6.2 Модель производительности
Производительность моделируется обратной величиной времени выполнения теста. Для данной архитектуры A, это время выполнение является произведением
|
|
|
времени цикла конструкции τA и счетчика циклов ССA: |
Счетчик циклов последовательной конструкции
В последовательной конструкции счетчик циклов обычно выражается как произведение итогового счетчика команд 1Cи среднего числа циклов CPI, которые требуются на команду:
CC = IC • CPI . (4.7)
Отношение CPI зависит от рабочей нагрузки и аппаратной конструкции. Схема выполнения набора команд Isопределяет, сколько циклов CPII требует в среднем команда I. С другой стороны, нагрузка вместе с компилятором определяет счетчик команд ICIдля каждой машинной команды, так что значение CPI может быть выражено как
|
|
где vI означает относительную частоту команды I при данной нагрузке.
Счетчик циклов конвейерных конструкций
Конвейеризация не ускоряет время выполнения одной команды, но она довольно таки значительно улучшает производительность команды из-за чередующегося выполнения. Таким образом, трудно непосредственно применить формулы (4.7) и (4.8) к конвейерной конструкции.
В случае совершенной конвейеризации, требуется (k-1) циклов для заполнения k-этапного конвейера. После этого команда завершается за один цикл. В этом случае счетчик циклов равен
CC = k - 1 + IC ~ IC.
Для очень длительной нагрузки счетчик циклов фактически равен счетчику команд. Однако, совершенная конвейеризация невозможна; конвейер должен иногда останавливаться для решения опасностей. Обратите внимание, что остановка появляется из-за аппаратной взаимной блокировки или из-за команд NOP, вставленных компилятором. Пусть vh означает относительную частоту опасности hпри данной нагрузке и пусть CPHhозначает среднее число остановленных циклов, вызванное этой опасностью. Тогда счетчик циклов конвейерной конструкции может быть выражен как
|
|
По аналогии с формулой (4.8), следующий терм рассматривается как отношение CPI конвейерной конструкции:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.