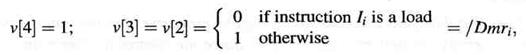Время цикла блока управления является максимальным из времен, требуемых механизмом останова и автоматом
tcon = max{Tstall , Tauto}.
По сравнению с последовательной конструкцией автомат меньше. Максимальная частота управляющих сигналов и максимальный коэффициент объединения по входу состояний урезаны на 25%, сократив время Tautoна 24% (таблица 4.16). Однако время цикла всего блока управления слегка увеличилось из-за механизма останова.
Окружения памяти Время цикла TMмоделирует время чтения и записи окружений памяти IMenv и DMenv. Конвейеризация не влияет на время tM , которое зависит от времен доступа к памяти dImem и dDmem:
tm = max{TIMenv,TDMenv}.
Пути данных DP Время цикла TDPявляется максимальным временем всех циклов в путях данных за исключением тех, которые проходят через блоки памяти. Оно включает этапы декодирования, выполнения и обратной записи:
TDP = max{TID, TEX, TWB].
В течении декодирования, конструкция DLX обновляет окружение PC (TPCenv), читает регистровые операнды (TGPRr), извлекает константы и определяет адрес назначения. Таким образом,
![]()
Таблица 4.16 перечисляет все эти времена циклов для последовательной и конвейерной конструкции DLX. Конструкция DLXπопределяет константу и адрес назначения уже в течении декодирования. Это сохраняет 4 вентиля задержки в циклах выполнения и обратной записи и улучшает общее время цикла на 6%.
Время цикла этапа ID является доминирующим в обновлении PC. В последовательной конструкции окружение ALU используется для увеличения PC и для вычисления адреса перехода. Так как окружение PCenv теперь имеет собственный сумматор и инкрементер, обновление происходит на 20% быстрее.
|
Итог 4.6 |
Конвейеризация имеет следующее воздействие на стоимость и время цикла ядра DLX с фиксированной точкой, исходя из предположения, что остальные опасности управления и данных могут быть решены программно:
• Пути данных становятся приблизительно на 12% дороже, но управление становится дешевле приблизительно на 30%. Так как управление составляет 5% от всей стоимости, конвейеризация увеличивает стоимость ядра примерно на 8%.
• Время цикла уменьшается на 6%.
Для анализа воздействия, которое конвейеризация имеет на качество ядра DLX с фиксированной точкой, мы должны количественно определить производительность двух конструкций. Для последовательной конструкции это было сделано в [MP95]. Для конвейерной конструкции производительность сильно зависит от того, как могут быть решены опасности данных и управления. Это анализируется в разделе 4.6.
4.4 Пересылка результата
В этом разделе мы опишем довольно простое расширение аппаратных средств машины DLXπ , которое позволит значительно ослабить гипотезу теоремы 4.5. На самом деле для новой машины мы покажем теорему 4.5 но со следующей гипотезой: Если команда Ii читает регистр GPR[r], тогда команды Ii-1 , Ii-2не являются операциями загрузки с адресатом GPR[r].
|
Теорема 4.7 |
Предположим, что для всех i>= 0 и r=/=0, команды Ii-1 , Ii-2 не являются операциями загрузки с адресатом GPR[r], где GPR[r] – исходный операнд команды Ii. Тогда для всех циклов Т и T', для всех этапов k и для всех команд Ii применимы следующие два требования, при
|
|
1. Для всех сигналов S на этапе k которые являются входами в регистр R € out(k) обновление происходит в конце цикла Т:
|
|
2. Для всех регистров и R € out(k) которые являются видимыми или обновленными в конце цикла Т:
![]()
4.4.1 Флаги правильности
Сперва мы введем три новых, вычисляемых заранее управляющих сигнала v[4 : 2] для подготовленной последовательной машины DLXσ. Сигнал правильности v[j] показывает, что данные, которые будут записаны в файл регистров на этапе 4 (обратная запись), уже доступны в цепях этапа j. Для команды Ii, сигналы правильности определяются как
|
|
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.