Практика 10.
Дискриминантный и кластерный анализ в системе Statistica.
1. Дискриминантный анализ.
Дискриминантный анализ относится к методам классификации многомерных наблюдений при наличии обучающих выборок (в отличие от кластерного анализа, осуществляющего классификацию автоматически - без обучения). Его цель состоит в идентификации новых объектов и их отнесении к уже имеющимся группам или совокупностям.
Например, при исследовании предприятий в одной из отраслей получен ряд групп, разбитых по степени эффективности производства; задача дискриминантного анализа - классифицировать новые предприятия путем отнесения к одному из уже имеющихся классов.
Считается, что дискриминантный анализ дает наилучшие результаты тогда, когда исходные данные удовлетворяют следующим требованиям, которые, однако, не являются обязательными:
Рассмотрим основные этапы проведения дискриминантного анализа на следующем примере.
Пример 1. Ниже
приведена таблица с данными условной классификации 12 стран мира по уровню
медицинского обеспечения населения. Страны условно разбиты на три группы в
соответствии с высоким, удовлетворительным и низким уровнем медицинского
обеспечения на основе следующих показателей: 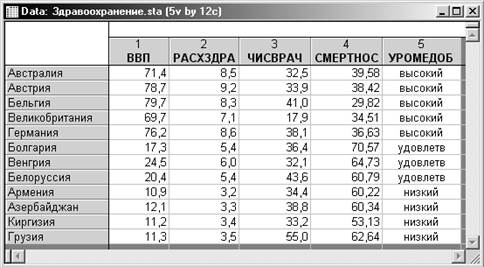
ВВП - ВВП, определенное на основе паритета покупательной способности, в % к США;
РАСХЗДРА - расходы на здравоохранение, в % к ВВП;
ЧИСВРАЧ - число врачей на 10 тыс. человек населения;
СМЕРТНОС - смертность населения по причине болезней органов кровообращения на 100 тыс. человек населения.
В первую группу с высоким уровнем медицинского обеспечения вошли промышленно развитые страны Запада: Австрия, Бельгия, Великобритания, Германия и Австралия. Вторую группу с удовлетворительным уровнем составили: Болгария, Венгрия, Белоруссия. Третья группа образована кавказскими и среднеазиатскими странами бывшего СССР: Армения, Азербайджан, Киргизия, Грузия («низкий» уровень).
Задача состоит в том, чтобы классифицировать страны: Россию, Грецию, Данию и Казахстан.
Шаг 1. Запустим модуль Дискриминантный анализ (Discriminant Analysis) и выберем переменные.
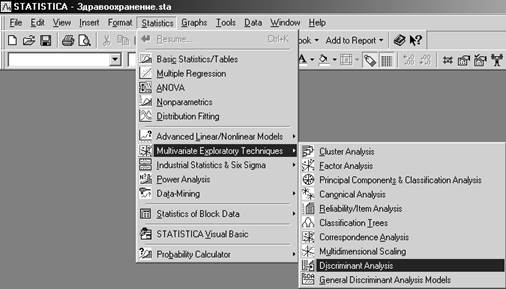
В нашем примере группирующей переменной является УРОМЕДОБ - уровень медицинского обеспечения, а независимыми - ВВП, РАСХЗДРА, ЧИСВРАЧ, СМЕРТНОС.
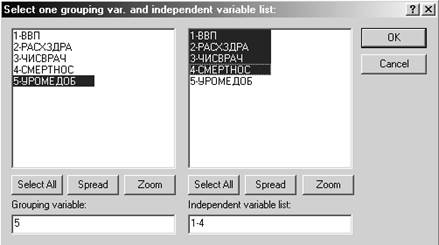
Шаг 2. Зададим Коды для группирующей переменной и включим (поставим галочку) Пошаговый анализ.
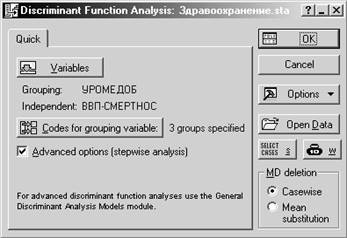
Шаг 3. В этом окне определим параметры модели и нажмем ОК.
В окошке Метод (Method) можно выбрать один из трех методов анализа: стандартный (Standard), пошаговый с включением (Forward stepwise) и пошаговый с исключением (Backward stepwise).
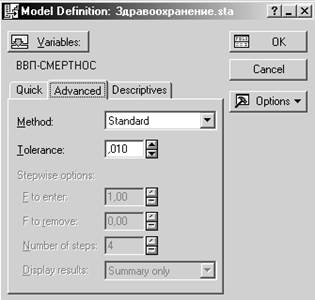 Если выбран Стандартный
метод, то все выбранные переменные будут одновременно включены в
модель.
Если выбран Стандартный
метод, то все выбранные переменные будут одновременно включены в
модель.
В методе Пошаговый с включением на каждом шаге в модель выбирается переменная с наибольшим F-значением, при этом пользователь должен установить его минимальную величину. Процедура заканчивается, когда все переменные, имеющие F-значение больше значения, указанного в поле F to enter, вошли в модель.
Если выбран Пошаговый анализ с исключением, то в уравнение будут включены все выбранные пользователем независимые переменные, которые затем удаляются в зависимости от величины F-значения. Переменная с наименьшим значением исключается из модели первой. Шаги заканчиваются, когда нет переменных, имеющих F-значение меньше определенного пользователем в поле F to remove. Заметим, что значение в поле F to enter всегда должно быть больше, чем значение в поле F to remove.
Поле Число шагов (Number of steps) определяет максимальное число шагов анализа, по достижении которых процедура закончится, даже если еще не все переменные прошли отбор на основе их F-значений.
Поле Толерантность (Tolerance) позволяет исключить из модели неинформативные переменные.
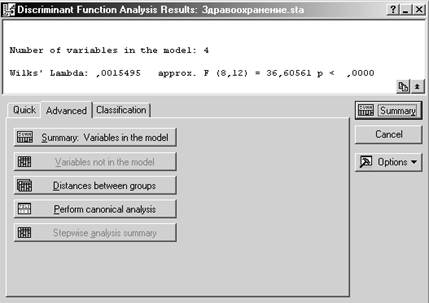 Шаг 4.
Шаг 4.
Статистика лямбда Уилкса служит для проверки качества дискриминации (чем ближе к 0, тем меньше вероятность ошибочного разделения).
Кнопки:
Переменные в модели
Переменные вне модели
Расстояния между группами
Канонический анализ и графики
Результаты пошагового анализа
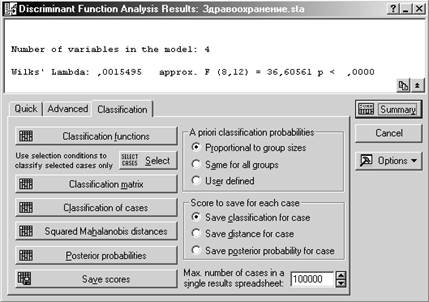
Кнопки:
Функции классификации
Матрица классификации
Классификация наблюдений
Квадраты расстояний Махаланобиса
Апостериорные вероятности
Сохранить результаты
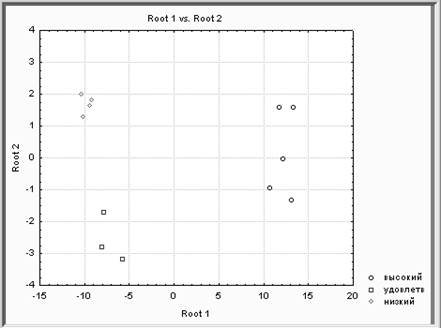
Шаг 5. Нажав кнопку Канонический анализ и графики можно посмотреть график рассеяния канонических значений для канонических корней.
Шаг 6. Определить принадлежность классифицируемых наблюдений к определенному классу можно, воспользовавшись опцией Функции классификации.
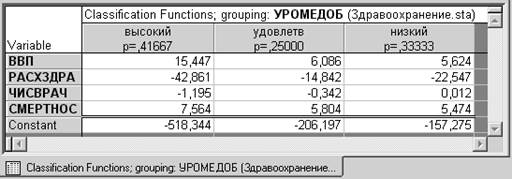
Например, оценки квалификационной функции для группы наблюдений «высокий» имеет следующий вид:
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.