Наряду с этим технология Intel Wide Dynamic Execution подразумевает эффективное использование технологии слияния, объединяющего микро- и макро-операции в единые исполняемые макро-операции. Если в предыдущих поколениях процессоров каждая входящая инструкция декодировалась и исполнялась отдельно, то теперь использование принципа слияния в процессе декодирования команд позволяет объединить пары некоторых инструкций в единую внутреннюю инструкцию – микрооперацию (micro-op). Суть этой технологии заключается в том, что если некоторая команда Х86 распадается на зависимые друг от друга микрокоманды, декодер осуществляет их привязку друг к другу. Такие последовательности микроинструкций, связанные технологией micro-ops fusion (микрослияния) для исполнения процессором в определенном порядке, представляются процессором на всех ступенях конвейера (кроме ступеней непосредственного исполнения) одной командой. Это позволяет избежать ненужных простоев конвейера в случае, если связанные микроинструкции оказываются оторванными друг от друга в результате работы алгоритмов внеочередного исполнения. Эта технология напоминает технологию SIMD, но используемую на уровне микрокоманд.
Кроме технологии micro-ops fusion, микроархитектура Core использует технологию macro-ops fusion. Данная технология призвана увеличить числа исполняемых за такт команд, и заключается в том, что ряд пар связанных между собой последовательностей Х86 инструкций, таких, например, как инструкция операции сравнения со следующей за ней инструкцией условного перехода, представляются одной микроинструкцией. Такая микроинструкция рассматривается планировщиком (scheduler) и выполняется на исполнительном устройстве как одна команда. Таким путем достигается как увеличение темпа исполнения кода, так и некоторая экономия энергии. Иллюстрация реализации технологии macro-fusion на примере слияния инструкции сравнения и, следующей за ней, инструкции условного перехода приведена на рис.XII.2. На нём показано, как за один такт декодируются и поступают в блоки постпроцессора одновременно пять инструкций Х86. В случае возможности слияния двух команд (macro-fusion), появляется фактическая возможность параллельной обработки 5 инструкций за такт (единовременно может образовываться не более одной макрокоманды, образованной способом слияния). Правда, такая возможность практически реализуема не для всех команд.
2. Технология Intel Advanced Digital Media Boost
(Усовершенствованная обработка мультимедийной информации)
В архитектуре Intel Core подверглись совершенствованию и блоки исполнения SIMD инструкций (SSE, SSE2, SSE3, SSE4). Эти инструкции широко используются в программном обеспечении при обработке изображений, видео и звука, шифрования, научной и финансовой деятельности. Они позволяют работать со 128 – битовыми операндами различного назначения (векторами и целочисленными либо вещественными данными повышенной точности).
До этого процессоры Intel исполняли одну SSE инструкцию, работающую со 128 – битовыми операндами лишь за 2 тактовых интервала. Один такт требовался на обработку старших 64 бит, а второй – на обработку младших 64 бит. Новая же архитектура Intel Core позволяет ускорить работу с SSE инструкциями в два раза, поскольку исполнительные блоки SSE стали полностью 128 – битовыми.
|

Рис. XII.2 Иллюстрация реализации технологии macro-fusion в
процессорах с архитектурой Intel Core.
Это усовершенствование существенно увеличило быстродействие процессора, особенно в тех приложениях, которые используют SIMD инструкции наиболее активно. Это относится, прежде всего, к различного рода мультимедиа – приложениям.
Иллюстрация реализации удвоенной скорости выполнения SIMD команд приведена на рис. XII.3.
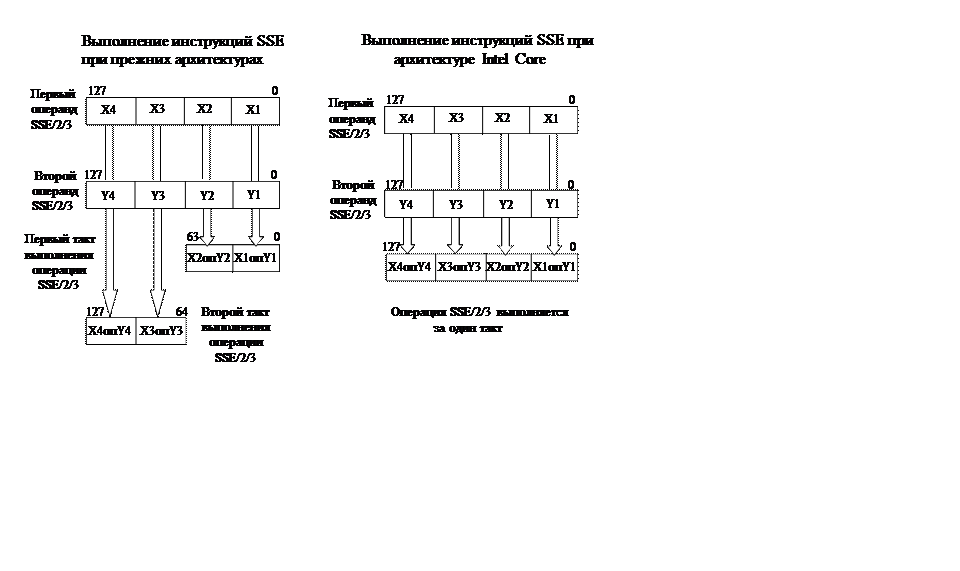
Рис.XII.3 Иллюстрация выполнения SIMD команд за один такт
в процессорах с архитектурой Intel Core
Следует заметить, что помимо увеличения скорости работы блоков исполнения SIMD команд, Intel дополнила существующий набор инструкций SSE3 еще восемью новыми инструкциями.
3. Технология Intel Advanced Smart Cache
(Усовершенствованный рациональный кэш)
МП с микроархитектурой Intel Core с самого начала создавались как двуядерные МП, каждый со своей памятью кэш L1. При этом у каждого ядра кэш L1 для команд и для данных были разделены. Однако память кэш L2 у этих двуядерных процессоров имеется одна и организована она таким образом, что может использоваться как первым ядром, так и вторым. Это дает сразу же несколько преимуществ.
Во-первых, у процессора появляется возможность гибко регулировать размеры областей кэш L2, используемых каждым из ядер. Доступ ко всему объему кэш L2 может получить любое из ядер процессора с микроархитектурой Intel Core. Таким образом, если одно ядро бездействует (например, в случае динамического отключения при изменении нагрузки на процессор), то второе ядро получает в свое полное распоряжение весь объем памяти кэш L2. Если же работают одновременно два процессорных ядра, то кэш L2 делится между ними пропорционально, в зависимости от частоты обращения каждого ядра к оперативной памяти. При этом, если оба ядра работают синхронно с одними и теми же данными, то хранятся они в общем кэш L2 только однократно. Следовательно, такой разделенный между двумя ядрами, кэш L2 используется гораздо эффективнее, чем отдельные кэш L2 для каждого ядра.
Во-вторых, использование объединенной памяти кэш L2 значительно снижает нагрузку на оперативную память и системную шину. Это объясняется тем, что в этом случае перед системой не стоит задача контроля и когерентности (целостности, соответствия) содержимого кэш-памяти различных ядер. Дело в том, что в системах с двуядерными процессорами и раздельными кэш L1, если оба ядра работают с одними и теми же данными, эти данные дублируются в кэш памяти каждого из ядер. Следовательно, прежде чем извлечь такие данные из кэш для обработки, каждое процессорное ядро должно проверить, не изменило ли эти данные другое ядро. Если произошло изменение, то требуется обновление содержимого кэш-памяти, которое в системах с двуядерными МП архитектуры NetBurst (но с раздельными памятями кэш L2) выполняется через системную шину и оперативную память. Общий же на два ядра кэш L2 позволяет полностью отказаться от этого неэффективного алгоритма. Микроархитектура Intel Core позволяет осуществить более простой обмен данными между кэш L1 каждого из ядер, через общий кэш L2, что дает гораздо большую результативность взаимодействия ядер при совместной работе над одной задачей.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.