|
Процессор |
Тактовая частота, МГц |
Размер кэш L2, Мбайт |
Частота шины, МГц |
Типичное тепловыделение Вт |
|
Core 2 Extreme X 6800 |
2,93 |
4 |
1066 |
75 |
|
Core 2 Duo E 6700 |
2,67 |
4 |
1066 |
65 |
|
Core 2 Duo E6600 |
2,4 |
4 |
1066 |
65 |
|
Core 2 Duo E6400 |
2,13 |
2 |
1066 |
65 |
|
Core 2 Duo E6300 |
1,86 |
2 |
1066 |
65 |
В конце 2007 года фирмой Intel разработана более усовершенствованная микроархитектура Enhanced Intel Core Microarchitecture, и в 2008 г начался выпуск микропроцессоров с этой микроархитектурой на основе нового, 45-нанометрового технологического процесса с использованием принципиально новых материалов (кодовое наименование этого семейства микропроцессоров – Penryn).
Новая линейка двуядерных микропроцессоров Intel Core 2, под маркировкой E6X50, выпущенная в 2008 г, имеет FSB, равную 1333 МГц. При этом тактовые частоты процессоров этой линейки равны: E6850 – 3,0 ГГц; E6750 – 2,66 ГГц; E6550 – 2,33 ГГц. В 2008 г появились и новые четырехъядерные процессоры Q6600, QX6850 и QX9650 (последние два имеет шину с частотой 333 МГц). Более подробно, характеристики микропроцессора QX9650 и QX6850 приведены в табл. XII.2.
Таблица XII.2
|
Микропроцессор |
Intel Core 2 Extreme QX9650 |
Intel Core 2 Extreme QX6850 |
|
Техпроцесс |
45 нм high-k |
65 нм |
|
Микроархитектура |
Enhanced Intel Core |
Intel Core |
|
Кодовое название |
Yorkfild XE |
Kentsfild |
|
Количество ядер |
4 |
4 |
|
Тактовая частота |
3,0 ГГц |
3,0 ГГц |
|
Частота FSB |
1333 МГц |
1333 Мгц |
|
Объем кэш-L2 |
(2×6 Мбайт) = 12 Мбайт |
(2×4 Мбайт) = 8 Мбайт |
|
TDP процессора |
130 Вт |
130 Вт |
Обобщенная блок-схема микропроцессора с архитектурой Intel Core 2 Duo приведена на рис. XII.1. На рисунке выделены следующие блоки.
Instruction Fetch and PreDecode – выборка инструкций и предварительное декодирование.
Instruction Queue – очередь инструкций.
Decode – блок декодирования.
μCode ROM – память микропрограмм.
Rename/Allocate–блок переименования и распределения дополнительных регистров.
RetirementUnit (ReOrderBuffer) - блок дополнительных, скрытых регистров (буфер или пул инструкций, выполняемых не в порядке поступления).
Schedulers–планирование и распределение микрокоманд по исполнительным устройствам.
ALUBranch, MMX, SSE, FPmove – исполнительное устройство, осуществляющее выявление необходимости перехода, а также простые операции с вещественными числами (перемещения и присвоения) и операции с операндами SIMD.
ALUFAdd, MMX, SSE, FPmove – исполнительное устройство, осуществляющее операции перемещения, присвоения и сложения, вещественных чисел, а также операции с операндами SIMD.
ALUFMul, MMX, SSE, FPmove – исполнительное устройство, осуществляющее, кроме операций перемещения и присвоения, сложные операции с вещественными числами (умножение, деление и др.), а также операции с операндами SIMD.
Load и Store – устройства, через которые происходит обмен данными между кэш памятью L1 данных и буфером дополнительных регистров.
Core 2M/4M shared L2 Cache – кэш память L2, разделяемая обоими ядрами, емкостью 2 или 4 Мбайт, с быстродействием до 10,4 Гбайт в секунду.
На 4 декодера (один для сложных инструкций и 3 для простых) микроархитектура предполагает наличие 6 портов запуска на исполнения (один – Load, два – Store и три универсальных).
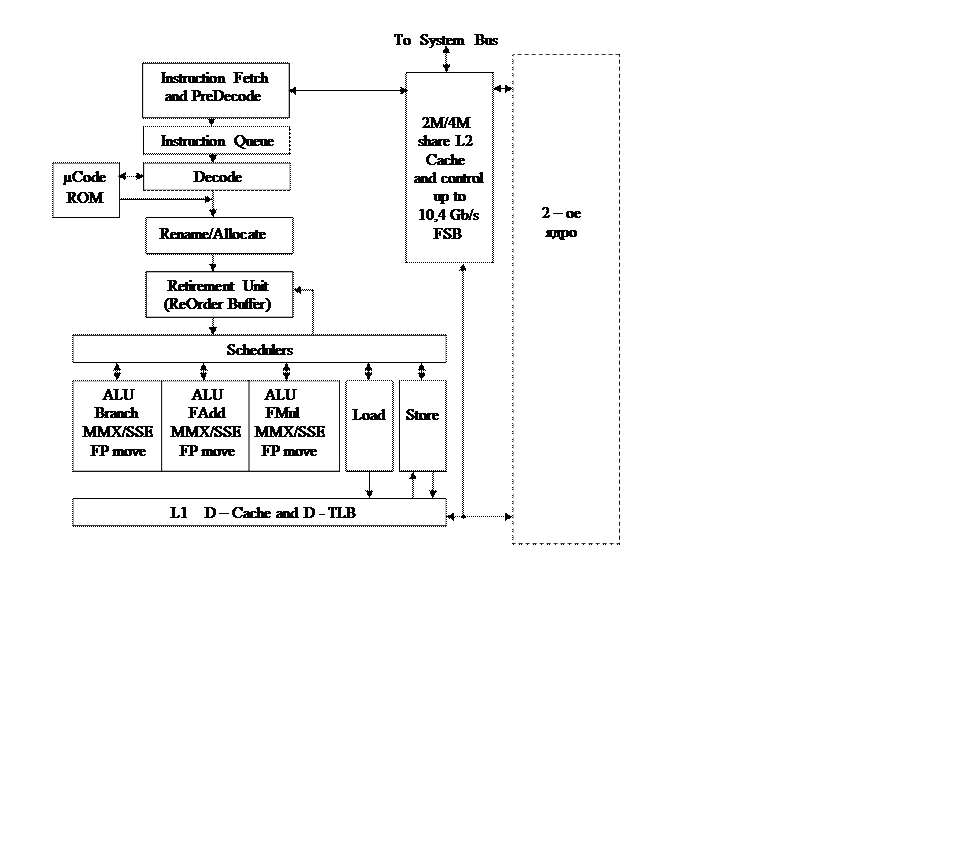
Рис.XII.1 Обобщенная блок схема микропроцессора с архитектурой
Intel Core 2 Duo.
Говоря о динамическом исполнении инструкций в процессорах архитектуры Р6 (Pentium Pro, Pentium II, Pentium III), Intel подразумевала принципиально новую суперскалярную архитектуру, способную выполнять анализ потоков кода, предсказания переходов и обладающую возможностями спекулятивного (упреждающего) и внеочередного исполнения команд.
В архитектуре NetBurst (Pentium 4), Intel использовала так называемую «усовершенствованную» методику динамического исполнения, которая помимо указанных выше свойств обладала более глубоким уровнем анализа кода и значительно улучшенными алгоритмами предсказания переходов (динамическим предсказанием, с учетом статистики ранее осуществленных переходов).
В новой архитектуре Intel Core используется, так называемое «широкое» динамическое исполнение. Широким его назвали потому, что процессоры архитектуры Core смогут исполнять больше операций за такт, чем их предшественники. Благодаря добавлению в каждое ядро дополнительного декодера и исполнительных устройств, каждое из ядер может выбирать из программного кода и исполнять до 4 инструкций Х86 одновременно.
Рассмотрим теперь основные типы новых технологий, которые использованы при создании микропроцессоров архитектуры Intel Core 2 Duo.
1. Технология Intel Wide Dynamic Execution.
(Широкое динамическое исполнение)
Основная задача этой технологии – обеспечить выполнение большего количества команд за каждый такт работы процессора, повышая эффективность исполнения приложений и сокращая его энергопотребление. Каждое ядро процессора, поддерживающего эту технологию, теперь может выполнять до 4 инструкций одновременно с помощью 14 ступенчатого конвейера. Эта технология также подразумевает расширенный анализ данных, спекулятивное, внеочередное выполнение команд и другие приемы, впервые реализованные фирмой Intel в архитектуре P6 (Pentium Pro, Pentium II, Pentium III), а также в архитектуре NetBurst (Pentium 4). В архитектуре Intel Core, кроме увеличения выполняемых одновременно инструкций с 3 (NetBurst) до 4, осуществляется более точное предсказание ветвлений и более глубокое буферирование команд, придающее дополнительную гибкость процессу исполнения инструкций.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.