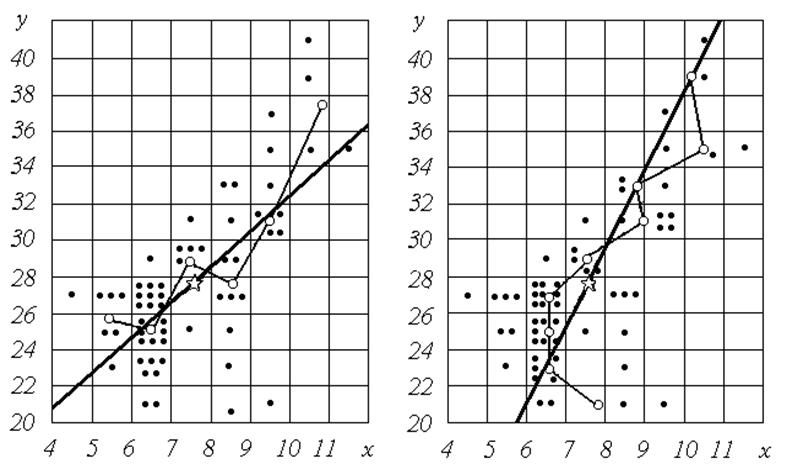
Графіки емпіричних ліній регресії приведені на рис. 2, 3. Зауважимо, що вузли емпіричних ліній регресії є центри відповідних класів (вертикальних або горизонтальних смуг). Облако розсіювання точок витягнуте вздовж деякої осі (діагональної регресії). Спосіб побудови діагональної регресії буде описаний у наступних розділах. Візуально переконуємося, що більшим значенням однієї змінної, як правило, відповідають більші значення іншої змінної.
Продовжуємо розрахунки параметрів лінійної моделі. З табл. 4 виписуємо обчислені суми (в умовних змінних):
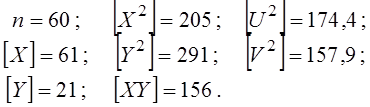
Ділимо ці суми на n=60 і одержуємо середні:
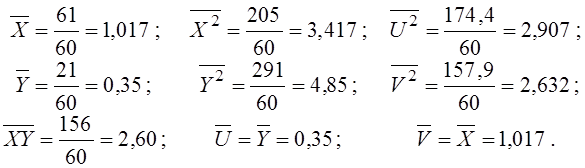
Тепер обчислюємо дисперсії (за формулою “середній квадрат” мінус “квадрат середнього”) і коваріацію (за формулою “середній добуток” мінус “добуток середніх”):
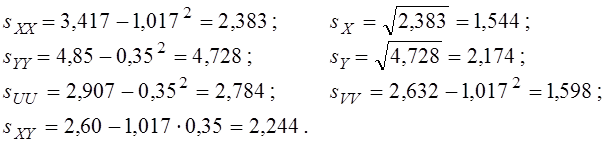
Робимо зворотний перехід до вихідних змінних:
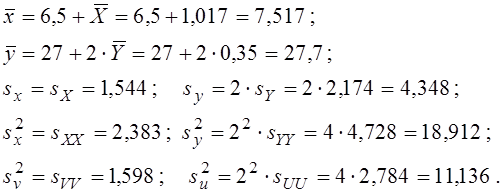
Коефіцієнт кореляції – величина безрозмірна і не змінюється при переході до реальних змінних:
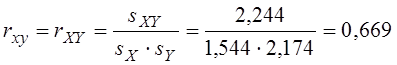 .
.
Угруповання даних дозволило досить просто виконати вищенаведені розрахунки, однак при цьому було припущено деяких похибок, оскільки дані, що попадають в одну клітинку, осереднювались на її центр. Для оцінки похибок угрупувань за вихідними даними цього ж прикладу були зроблені розрахунки на ЕОМ (без угрупувань). Порівняємо отримані результати:
|
Точний |
За згрупованими даними |
Погрішність |
|
xcp = 7,432 |
xcp = 7,517 |
1,1% |
|
ycp = 27,679 |
ycp = 27,700 |
0,1% |
|
sx = 1,527 |
sx = 1,544 |
1,1% |
|
sy = 4,294 |
sy = 4,348 |
1,3% |
|
rxy = 0,705 |
rxy = 0,669 |
–5,1% |
Будемо мати на увазі, що подвійне угрупування даних по сітці порядку 10´10 призводить приблизно до 5%-вої похибки.
Тепер обчислюємо коефіцієнти регресії y по x :
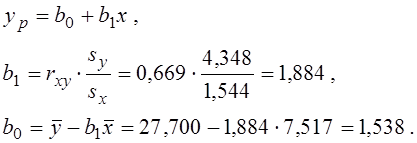
Отримано рівняння регресії (рівняння кореляційної залежності)
yp = 13,538 + 1,884 x .
Графік цієї лінії наведений на рис. 4 разом із графіком відповідної емпіричної залежності. Зауважимо, що вузли емпіричної лінії групуються навколо лінії регресії.
Для прикладу обчислимо параметри спряженої залежності:
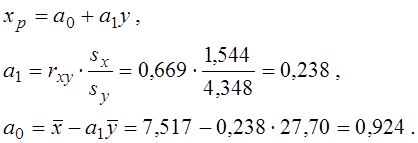
Графік спряженої залежності наведений на рис.5 разом із графіком відповідної емпіричної лінії регресії.
|
Рис. 4. Регресія y по x |
Рис. 5. Регресія x по y |
||
|
–––○––– |
Емпірична лінія yx |
–––○––– |
Емпірична лінія xy |
|
▬▬▬ |
Теоретична лінія |
▬▬▬ |
Теоретична лінія |
Нарешті розрахуємо параметри діагональної “регресії”:
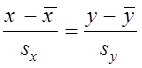 ,
,
чи y = c0 + c1 x ,
де
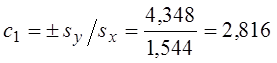 (знак ± вибирається за знаком rxy),
(знак ± вибирається за знаком rxy),
![]() .
.
Графік діагональної регресії наведений на рис. 6; ця лінія збігається з головною віссю облака розсіювання емпіричних точок.
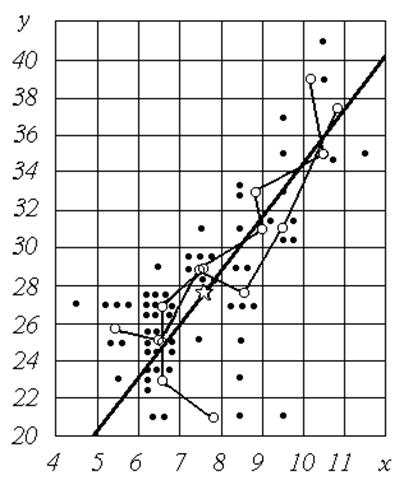
Рис. 6 Діагональна й емпіричні лінії регресії
Мета цього розділу – зробити всі статистичні висновки після формальної оцінки параметрів моделі і дисперсії залишку. Передусім варто перевірити значущість і адекватність моделі, для чого існують готові формули. Розглянемо послідовність викладок дисперсійного аналізу в табличній формі, оскільки деякі програми статистичного аналізу (наприклад, відомий ППП Статграф) видають результати саме так.
Таблиці дисперсійного аналізу (одновимірного дисперсійного аналізу) уніфіковані, мають однакові графи і заголовки. Нижче, для нашого прикладу, що аналізується послідовно, наведена таблиця дисперсійного аналізу I для перевірки значущості кореляційного зв’язку y по x (табл. 5). Розглянемо детально всі елементи цієї таблиці.
У цьому прикладі наявні дані (60 спостережень) були згруповані на 6 класів за різними значеннями аргументу x. Тепер ці дані можна представити таким чином
yij = ui + e ij ,
де yij - значення, що спостерігаються (“повний сигнал”); ui – середні по групах (“корисний сигнал”); e ij – випадкові похибки (“шум”).
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.