Лучший способ понять, как происходит синхронное озвучивание, заключается в следующем — откройте и проанализируйте файл с примером. В нем можно найти визуальное представление волновой формы звука (маленькая волнистая "чепуха"), с помощью которого определяется, каким участкам временной шкалы соответствуют голосовые максимумы, а каким — минимумы. Также можно заметить, что голос вводится как отдельный элемент, и располагается на отдельном слое, изолированном от фоновых звуков или музыки. Если еще до импортирования во Flash голос был смешан с другими звуками, будет невозможно увидеть временную диаграмму звуковой волны собственно голоса, так как она накладывается на профили остальных звуков. Если создается мультфильм с участием нескольких персонажей, то голос каждого из них лучше всего записать отдельно, особенно в случаях, когда они говорят одновременно. Такое отделение предоставит вам больше возможностей контроля отдельных звуков при анимировании. В действительности на слои разбивается весь мультфильм, чтобы облегчить его редактирование. Для каждого важного элемента выделяется по крайней мере один слой. Кроме того, для звуковой дорожки со звуком бонго установлен режим синхронизации Event (Событие). В результате данная дорожка не будет воспроизводиться при "прочесывании" временной шкалы — вы услышите только голосовую дорожку, что позволит правильно согласовать ее с анимацией. Если для обеих дорожек задать режим Stream (Поток), то будет труднее сосредоточиться на одном голосе. (Когда синхронизация будет завершена, не забудьте вернуть звук бонго в режим Stream или просто удалите этот слой на время, пока не будет анимирован рот.)
Фонемы
Теперь займемся фонемами. Существует несколько стандартных положений рта, представляющих большинство основных звуков (рис. 14.15). Их использование не является обязательным, но они обеспечивают твердый базис, с которого можно начинать овладевать искусством синхронного озвучивания на более профессиональном уровне. Итак, сначала заметим, что слово Meyers (Майерс) начинается в 12 кадре нашего мультфильма. Звук "мммм" лучше всего представлен, когда нижняя губа подвернута слегка под верхнюю губу. Попробуем сказать "мммм” самостоятельно, чтобы убедиться в этом. В слове Meyers это "мммм" звучит на протяжении двух кадров и затем следует долгий звук / (аи). Заметим, что озвучивание согласно произношению по английским буквам е-у-е сложнее, чем нам нужно, поэтому мы не будем этого делать. Слово Meyers обычно произносится как M-I-ER-Z (М-АЙ-ЕР-3), причем звук ER начинается как упрощенный звук i (рот сохраняет прежнюю форму, но становится немного меньше по мере замирания фонемы). Слово заканчивается фонемой Z, для которой рисуется просто слегка открытый рот, с языком в верхней его части.
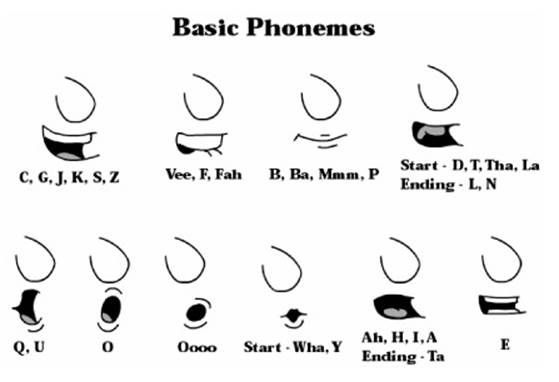
Рис. 14.15. Для синхронного озвучивания можно комбинировать нескольких основных фонем
Далее следует фраза "very talented", которая произносится в виде быстро проговариваемых слогов. Выделите на каждый слог только один кадр, используя при этом каждый доступный кадр. Заметим, что как для звука Т (Т), так и для звука L (Л), самое выразительное движение — когда язык касается неба. Поскольку Т и L характеризуются почти одинаковым положением рта, мы можем позволить себе роскошь дублирования кадров. Для звука V (В) требуется такая же основная форма рта, как и для звука М, — так что скопируйте рисунок рта, использованный для звука М в слове Meyers. Для звука В (Б) из слова bongo можно использовать такое же положения рта, как и для звуков М и V, однако для этого звука мы не будем применять копирование. Для него мы нарисуем новый рот, в который внесем некоторые особенности, чтобы персонаж не выглядел, как говорящий автомат. Основное искусство, требуемое при синхронном озвучивании, — это умение правильно определить, какую часть положений рта копировать, а какую — рисовать заново. Говоря коротко, это искусство основано на балансировании между количеством новых иллюстраций, которые вы вводите в проект, и предотвращением очевидного повторения.
Озвучивание остальной части фразы я предоставляю читателю. При выполнении этого задания, конечно, захочется повторно использовать многие из предоставленных положений рта. При этом нужно помнить, что наиболее решающим фактором является требование синхронности. Оно позволяет определить, где необходимо новое положение рта, а где положение рта требует только доработки. Медленно просмотрите временную шкалу; если потребуются новые положения, их нужно нарисовать. Я настоятельно рекомендую делать такие рисунки самостоятельно, так как это хорошая практика для тех, кто решил стать профессионалом — мастером синхронного озвучивания.
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.