Федеральная таможенная служба Государственное образовательное учреждение высшего профессионального образования «Российская таможенная академии» Владивостокский филиал

Тема: Характеристики панельных данных. Линейные модели панельных данных. Модели с фиксированными и случайными эффектами
Выполнила: , студент 231 группы Владивосток 2014
Панельные данные
Панельные данные – разновидность пространственно-временных данных. Панельные данные содержат информацию об одних и тех же единицах, наблюдавшихся на протяжении нескольких периодов времени. Панельные данные (panel) – дословный перевод с английского языка «список». Данные представляют собой двумерные массивы, одно из измерений – «пространственное», по экономическим единицам ( i = 1, . . . , N ), другое — «временное», по времени ( t = 1, . . . , T ).
2
Причины интереса к панельным данным:
3
Известными примерами панельных данных являются:
– Американские базы NLS (National Longitudinal Surveys of Labor Market Experience) и PSID (University of Michigan’s Panel Study of Income Dynamics; – Российские базы RLMS или в русской аббревиатуре РМЭЗ (Российский мониторинг экономического положения и здоровья населения.
4
База NLS содержит данные по различным сегментам рабочей силы: мужчины от 45 до 59 лет на 1966 год, юноши от 14 до 24 лет на 1966 год, женщины от 30 до 44 лет на 1967 год, девушки от 14 до 24 лет на 1968 год и молодежь обоих полов от 14 до 21 года на 1979 год. Первые 4 сегмента периодически опрашивались в течение 15 лет. Последний сегмент продолжает наблюдаться. Перечень наблюдаемых переменных насчитывает 1000 наименований с точки зрения рыночного предложения рабочей силы.
5
База PSID
База PSID возникла на основе сбора годовой экономической информации из репрезентативной национальной выборки, охватывающей около 6000 семей и 15000 индивидуумов в 1968 году, которая пополняется до сих пор. Данные содержат около 5000 переменных, включая занятость, доход, переменные человеческого капитала, жилищные условия, мобильность и т.п.
6
База РМЭЗ представляет собой серию общенациональных, репрезентативных опросов, регулярно проводимых с 1992 года с целью систематического наблюдения воздействия российских реформ на динамику экономического благосостояния домохозяйств и отдельных индивидов. База данных РМЭЗ представляет результаты опросов свыше 10 тысяч человек. Информация, собранная в РМЭЗ, касается размеров, источников и структуры доходов и расходов домохозяйств, занятости, уровня образования, состояния здоровья и других характеристик (всего свыше 500 переменных).
7
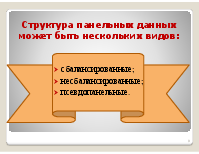
Структура панельных данных может быть нескольких видов:
8
Сбалансированные данные
Если она содержит информацию о каждом объекте в каждый период наблюдения, и несбалансированной в противном случае. Несбалансированные данные Если для некоторых объектов, или времени наблюдения отсутствуют (имеется «износ» выборки — кто-то переехал, кто-то умер, кто-то отказался участвовать в опросе, регионы или фирмы объединяются, фирмы могут обанкротиться). Псевдопанельные данные Если в различные моменты времени, наблюдаются различные экономические единицы.
9
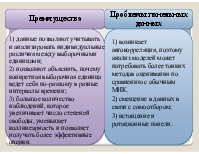
Преимущества
Проблемы панельных данных
1) данные позволяют учитывать и анализировать индивидуальные различия между выборочными единицами; 2) позволяют объяснять, почему конкретная выборочная единица ведет себя по-разному в разные интервалы времени; 3) большое количество наблюдений, которое увеличивает число степеней свободы, уменьшает коллинеарность и позволяет получать более эффективные оценки.
1) возникает автокорреляция, поэтому анализ моделей может потребовать более тонких методов оценивания по сравнению с обычным МНК. 2) смещение в данных в связи с самоотбором; 3) истощение и ротационные панели.
10
Базовая модель панельных данных
В общем виде регрессионная модель панельных данных имеет следующий вид: x it = Z it + a it + ε it , i = 1, . . . , N; t = 1, . . . ,T. где i — индекс экономической единицы (фирмы, страны и т.д.), t – время, a it – коэффициенты вектора объясняющих переменных, Z it в период t для выборочной единицы i.
11
Можно выделить специфические факторы (не наблюдаемые), которые относятся к моменту времени и к экономическим единицам, что позволяет учитывать индивидуальные особенности: x it = Z itα + γ t + f i + ε it , где Z it – n-мерный вектор регрессоров, не включающий константу, f i выражает индивидуальные эффекты экономических единиц, не зависящие от времени, γ t улавливает эффекты для тех переменных, которые имеют специфику
Уважаемый посетитель!
Чтобы распечатать файл, скачайте его (в формате Word).
Ссылка на скачивание - внизу страницы.